1-Intro
来自 Bytebytes Go 的一个总结
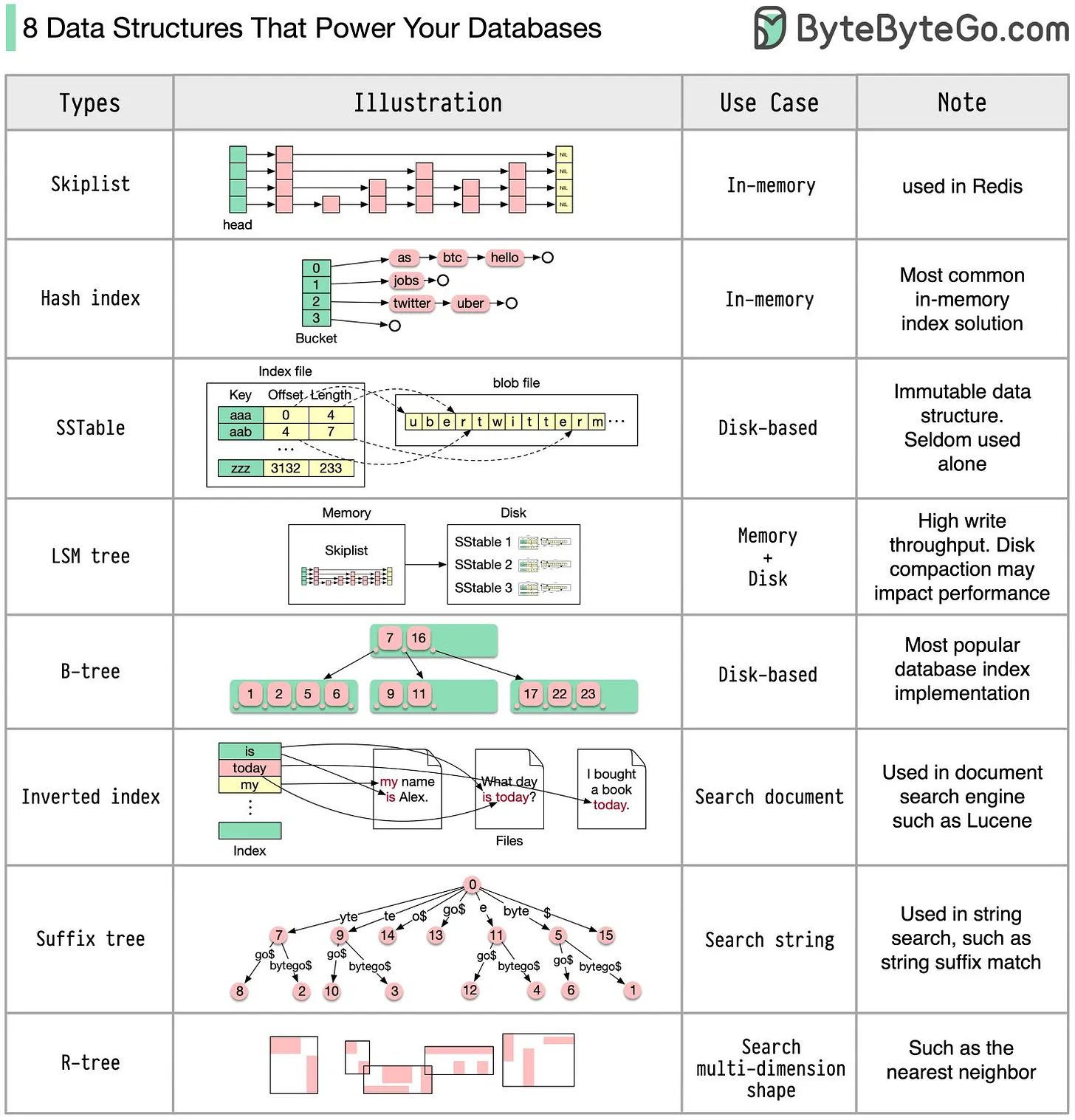
大多数的 Database 中都用到了这些数据结构,优化版本.
SkipList:Redis里面的SortedSet实现 ;Hash Index: 字典SSTable: Immutable-OnDisk Map Implementation , 有序LSM Tree:SkipList + SSTable, 不可变数据的顺序IO, 写入吞吐量非常高. 其中SkipList用于实现MemTable, 用于可变的数据实现.B-tree:Disk-Based Solution.Mysql 的 B+ Tree 索引,MongoDb 的 B Tree 索引都是其中的 佼佼者, 而且不仅仅是 磁盘,好像etcd同时使用了一个开源的B+ tree树磁盘存储 和Google的内存B+ Tree树 ;Inverted Index:Lucene的倒排索引Suffix Tree: 后缀树.String Pattern SearchR-Tree: 多维度搜索,例如Nearest neighbor
2-LCM In practise
Lcm 在当前实在是太流行了,所以我们重点描述一下
这里只是一个快速的 理解,真正的实现都复杂无比
LSM 伪代码实现
class LSMTree:
def __init__(self):
# MemTable在内存中,通常使用SkipList实现
self.memtable = SkipList()
# SSTables在磁盘上,层次化存放
self.sstables = []
def write(self, key, value):
# 处理写操作,先写入内存中的MemTable
self.memtable.insert(key, value)
# 当MemTable达到一定大小时,将其清空,并将数据写入磁盘形成新的SSTable
if self.memtable.is_full():
self.flush()
def flush(self):
# 将memtable的内容转换为SSTable并写入磁盘
sstable = self.memtable.convert_to_sstable()
self.sstables.append(sstable)
self.memtable.clear()
def read(self, key):
# 处理读操作,先从内存中的MemTable开始搜索
value = self.memtable.search(key)
if value is not None:
return value
# 如果在MemTable中未找到,则在SSTables中查找
for sstable in reversed(self.sstables):
value = sstable.search(key)
if value is not None:
return value
return None
-
一个
SkipList+ 一系列的SSTables的 伪代码实现. 实现了基本的write和read -
可以自己写一个
LCM, 不算太复杂, 这里有一个 Java 的版本, https://github.com/tomfran/LSM-Tree#possible-improvement
有些数据库还会混合使用,例如 Kudu, 属于变种的
LSM
Kudu 主要使用 LSM Tree 来优化写入性能,但是 所有的 LSM Tree 在处理随机读取性能的时候 都会有一些问题, 也导致了 LSM Tree 引发的三种 Compaction 问题和不同的策略, 三种问题 分为是 读扩散,写扩散和空间扩散.
Kudu会把数据写入到 位于内存的RowSet也就是LSM中的MemTable, 然后分批按照SSTable的结构落盘, 转化为不可变的DiskRowSetKudu本身是面向行的数据存储, 多个行组成一个类似.Tablet的单元, 对每个Tablet的单元都会维护一个meta-data, 其中包含了rowKey的范围和存储的数据文件, 并使用B+ Tree来索引, 用于在查询的时候快速定位- 更新和删除数据:
Kudu使用DeltaFile来存储更新或者删除的操作, 每个DiskRowSet有关联的DeltaFile, 然后在读取的会合并这个DeltaFile的结果 DeltaFile的概念比较独特,不属于传统的LSM,DeltaFile会和 他们对应的DiskRowSet对应- 同样的
DeltaFiles和DiskRowSet也会 有compaction. 正常的策略还是基于Size来的,如果DeltaFiles的数量大小超过一定 阈值就会触发Compaction, 基于 Sized-Base Merged 策略的数据库很多, 例如Es就仅仅支持这个, 一般读写性能都不错,但是可能会面临比较大的 空间扩散问题 ;
具体可以参考 Kudu-doc
我们使用
ScyllaDb来说明LCM Compaction Strategy的问题
三个问题:
- Read Amplification: 一份数据会在多个
SSTables中存在,读取的时候需要Merge,有BloomFilter加速 , 我们简称为RA, 读扩散 - Write Amplification: 一次写入要修改多次, 例如
Leveled策略, 简称为WA, 写扩散 - Space Or Size Amplification: 一份数据在多个
SSTables, 比如 8倍存储空间,我们称为 存储扩散 , 简称为SA
具体可以参考 RocksDB-Compaction
在取舍之后 有如下的方式来:
STCS:Size-Based策略,大多数的默认策略,例如Es;LCS:Small-Fixed-Size, 适合写少,读多,核心解决了SA问题 ;ICS:Incremental策略,集合了上面2种策略的优点,是ScyllaDB Enterprise的功能,适合大多数场景 ;TWCS:Time-Window时间窗口策略 ;
STCS
- 基于
sized是会按照大小分为几个档, 比如说bucket_low和bucket_high, 相同区间内的属于一个档位 ; - 如果某个档位的 的
SSTable数目 >min_thresold的时候, 会触发合并
我们来判断三个扩散问题. 假设, 我们有 N 个 SSTables .
写扩散: 我们会定时合并,所以大概是个 O(LogN) 级别的扩散 .
读扩散: 这个就要分析业务场景了. 我们是针对一个 Parition 不断的 Update 还是说我们虽然是 写比较多,但是都是写不会集中在某个 Partition, 其中比较恐怖:
对某一个 Parition 而言,有2种可能,在一个 Tier 的多个 SSTable . 还有可能就是在多个 Tier的多个 SSTable .
- 如果是一个
Tier, 这个时候BloomFilter算法很有用 - 多个的话,
BloomFilter也拯救不了
空间扩散: 这个是最严重的问题. Merge 是需要额外的存储的,最大的时候,可能是原本数据量的 8倍 16倍这种
LTCS
为了解决上面的问题,针对读多写少的场景 做的优化,增加写扩散.
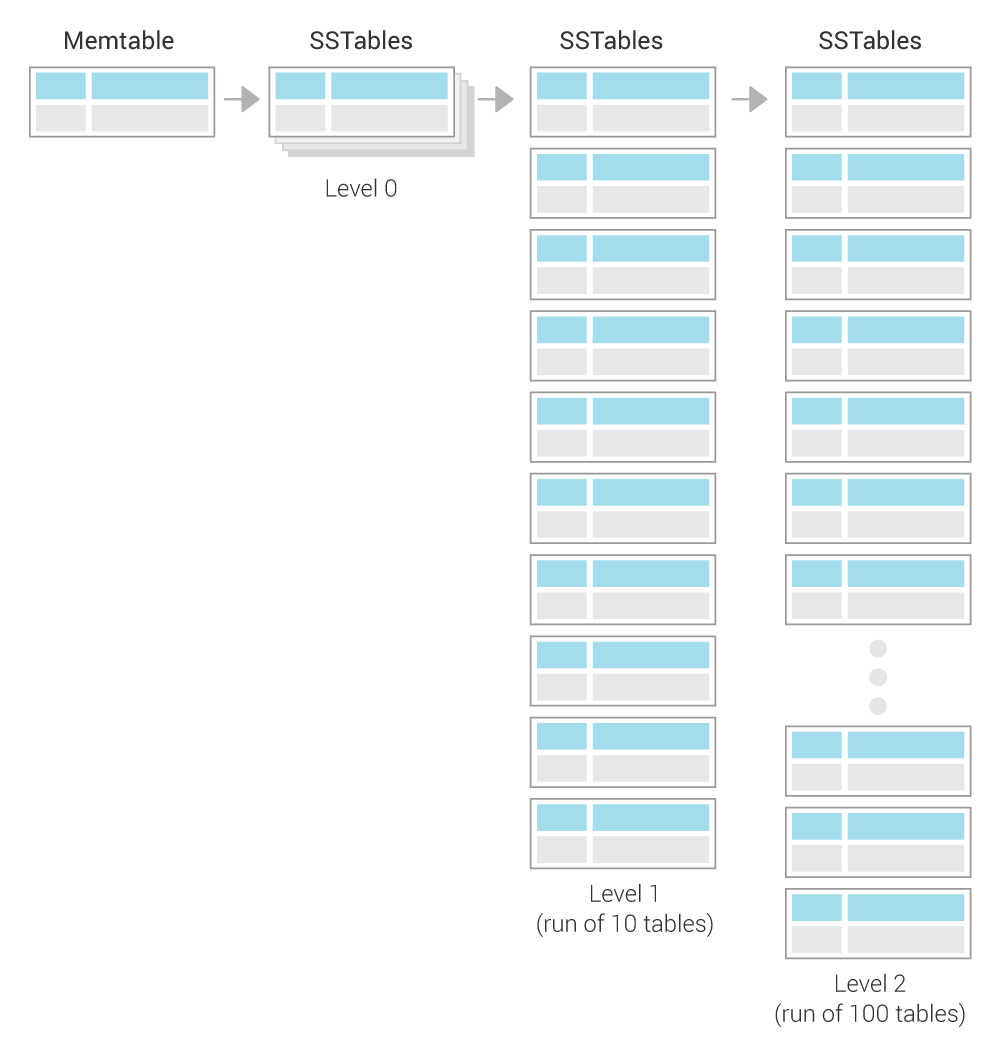
先分层,每一层的最小单位都是. 一样的 , 160MB 的 SSTable . 只是每一层的 SSTable 个数不同, 第一层10个,第二层100个. 每一层都是按 Key 分的,他们之间的 Key 区间互不相同
第0层比较特殊,是属于创建的区域. 当他有一定4个时候,就会触发分裂. 这里的数据会全部的写入到一层. 大致的流程如下:
- 并发的读
Level0和Level1的所有SSTables; - 通过
Merge生成新的Level1的SSTables; - 这次
Merge生成的不是一个超大的SSTable, 而是大小固定的160MB, 而且按照Key分割的 - 如果
Level1的超过了 10个,就触发二次Merge, 从Level1到Level2.
二次 Merge的流程,类似:
- 首选选1个我们在
Level1的目标SSTable; - 他一定有一个
KeyRange,这个这个去找Level2中的Target; - 和
Level2中大约 12 进行Merge, 和上面一样的,保证 大小160MB; - 超过 100个,触发 3次
Merge;
下图来自于 ScyllaDB .
工业上,使用
LTCS的话一般都会选 则 STCS 作为备选
因为 LTCS 会无法 实现 数据的快速写入, 由于多次 Merge 的存在增加了 写入的成本.
这个时候就会导致 Level0 这特殊的一层积累了大量的 SSTables , 而这会导致 读的速度也会很慢.
所以可以考虑配置一个阈值,用来控制 Level0 的最大数目,在大概 32个左右的时候可以把策略自动降级为 STCS
ICS 是对 STCS 的优化
STCS的问题是 因为SSTables在合并完成之前不能被完全删除, 这也是STCS的最大问题Space 扩散;ICS则是集合了LCS的优点来优化这个解,会把每个大的SSTable切分为一系列有序的,固定大小的 小的 SSTable .
具体的 Steps 可以参考 ICS-Enterprise , 是一个收费功能.
TWCS : 本质上是 每个时间窗口中使用
STCS
这个是 ScyllaDB 对时序数据库的支持.
时序数据库有一些特征.
- 例如是 不可变数据
- 时间上 基本有序,往往会在写入最新的分区
- 有的时序库还需要一个
TTL, 这意味着在Compaction的时候可以直接Delete
我们用一个实际的例子,来观察 TWCS 的特征
CREATE TABLE twcs.twcs (
id int,
value int,
text_value text,
PRIMARY KEY (id, value)
) WITH CLUSTERING ORDER BY (value ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'
AND comment = ''
AND gc_grace_seconds = 60
AND default_time_to_live = 600
AND compaction = {'compaction_window_size': '1',
'compaction_window_unit': 'MINUTES',
'class': 'org.apache.cassandra.db.compaction.TimeWindowCompactionStrategy'}- 我们定义了时间窗口是 1 分钟, 最多保留10个窗口
Ven 8 jul 2016 07:47:17 CEST
-rw-r--r-- 1 adejanovski staff 20567 8 jul 07:47 twcs-twcs-ka-1453-Data.db
=============
Ven 8 jul 2016 07:47:22 CEST
-rw-r--r-- 1 adejanovski staff 20567 8 jul 07:47 twcs-twcs-ka-1453-Data.db
-rw-r--r-- 1 adejanovski staff 21040 8 jul 07:47 twcs-twcs-ka-1454-Data.db
=============
Ven 8 jul 2016 07:47:27 CEST
-rw-r--r-- 1 adejanovski staff 20567 8 jul 07:47 twcs-twcs-ka-1453-Data.db
-rw-r--r-- 1 adejanovski staff 21040 8 jul 07:47 twcs-twcs-ka-1454-Data.db
=============
Ven 8 jul 2016 07:47:32 CEST
-rw-r--r-- 1 adejanovski staff 20567 8 jul 07:47 twcs-twcs-ka-1453-Data.db
-rw-r--r-- 1 adejanovski staff 21040 8 jul 07:47 twcs-twcs-ka-1454-Data.db
-rw-r--r-- 1 adejanovski staff 20856 8 jul 07:47 twcs-twcs-ka-1455-Data.db
=============
Ven 8 jul 2016 07:47:37 CEST
-rw-r--r-- 1 adejanovski staff 20567 8 jul 07:47 twcs-twcs-ka-1453-Data.db
-rw-r--r-- 1 adejanovski staff 21040 8 jul 07:47 twcs-twcs-ka-1454-Data.db
-rw-r--r-- 1 adejanovski staff 20856 8 jul 07:47 twcs-twcs-ka-1455-Data.db
-rw-r--r-- 1 adejanovski staff 20921 8 jul 07:47 twcs-twcs-ka-1456-Data.db- 我们每隔一段时间打印一下,发现在 第一个窗口
47minSSTables在不断的增加, 直到4个, 刚好 SCTS 默认就是4个触发. Merge, 然后真的 触发了 Merge
Ven 8 jul 2016 07:47:37 CEST
-rw-r--r-- 1 adejanovski staff 89474 8 jul 07:47 twcs-twcs-ka-1457-Data.db
=============- 触发了
Merge, 之前的数据全部被压缩到一个Tw中 - 而 不同时间窗口之间则是 独立的 STCS, 不会影响
Ven 8 jul 2016 07:49:12 CEST
-rw-r--r-- 1 adejanovski staff 180903 8 jul 07:48 twcs-twcs-ka-1463-Data.db
-rw-r--r-- 1 adejanovski staff 203792 8 jul 07:49 twcs-twcs-ka-1475-Data.db
-rw-r--r-- 1 adejanovski staff 19670 8 jul 07:49 twcs-twcs-ka-1476-Data.db
=============
Ven 8 jul 2016 07:49:17 CEST
-rw-r--r-- 1 adejanovski staff 180903 8 jul 07:48 twcs-twcs-ka-1463-Data.db
-rw-r--r-- 1 adejanovski staff 203792 8 jul 07:49 twcs-twcs-ka-1475-Data.db
-rw-r--r-- 1 adejanovski staff 19670 8 jul 07:49 twcs-twcs-ka-1476-Data.db
-rw-r--r-- 1 adejanovski staff 19575 8 jul 07:49 twcs-twcs-ka-1477-Data.db
=============
Ven 8 jul 2016 07:49:22 CEST
-rw-r--r-- 1 adejanovski staff 180903 8 jul 07:48 twcs-twcs-ka-1463-Data.db
-rw-r--r-- 1 adejanovski staff 203792 8 jul 07:49 twcs-twcs-ka-1475-Data.db
-rw-r--r-- 1 adejanovski staff 19670 8 jul 07:49 twcs-twcs-ka-1476-Data.db
-rw-r--r-- 1 adejanovski staff 19575 8 jul 07:49 twcs-twcs-ka-1477-Data.db
-rw-r--r-- 1 adejanovski staff 19714 8 jul 07:49 twcs-twcs-ka-1478-Data.db
=============
Ven 8 jul 2016 07:49:27 CEST
-rw-r--r-- 1 adejanovski staff 180903 8 jul 07:48 twcs-twcs-ka-1463-Data.db
-rw-r--r-- 1 adejanovski staff 203792 8 jul 07:49 twcs-twcs-ka-1475-Data.db
-rw-r--r-- 1 adejanovski staff 86608 8 jul 07:49 twcs-twcs-ka-1480-Data.db
=============下面给一个总结, 适合所有
LCM形式的数据库.
| Workload/Compaction Strategy | Size-tiered | Leveled | Incremental | Time-Window | Comments |
|---|---|---|---|---|---|
| Write-only | Y | N | Y | N | [1] and [2] |
| Overwrite | Y | N | Y | N | [3] and [4] |
| Read-mostly, with few updates | N | Y | N | N | [5] |
| Read-mostly, with many updates | Y | N | Y | N | [6] |
| Time Series | N | N | N | Y | [7] and [8] |
可以看到 STCS 是比较通用的.
- 如果使用
STCS,Write-Only的应用, 此时,SA一般是 2倍空间左右 ; - 如果是
LSCS, 而是Write-Only, 非常不建议,WA会非常严重; - 如果是使用
STCS, 然后业务又是OverWrite的场景, 那么SA会非常恐怖,可能经常是 数据量的 8倍左右 OverWrite场景同样也不适合LTCS,WA会膨胀
Refer
- LSM-Tree-Java: 一个手写的
LSM和SkipList等等实现 - RocksDB-Compaction: RocksDb 的
Compaction文档,其中描述了LSM的详细问题 - Scylladb Compaction Strategy