1-Intro
解决的 是图存储引擎的问题
核心是解决单机的图存储瓶颈
- 支持非常大的图,例如 200亿个节点.
- 有不错的水平扩展能力 ;
- 可以 集成
Hadoop做基于图的 离线oLAP; - 协议标准, 支持 tinkerpop 标准 ;
- 支持 标准的图语言
Gremlin, 例如字节等自研引擎基本都遵循这个 标准 ; - 解决了 superNode 问题 ;
- 做了磁盘的
optimized工作 - 更有趣的是 插拔的存储引擎 .
- Storage Backend
- Index Backend: 混合索引支持 地理位置,数据范围和全文搜索的支持
如果使用
Cassandra或者Scylladb作为存储引擎, 偏向CAP中的PA
- 无单点问题
- 可以和
Hadoop集成 - 水平扩展性很好,基本没有性能瓶颈
如果使用
HBase作为存储引擎, 偏向 数据的一致性 ,CAP中的PC
- 仅仅和
Hadoop集成,更完整的生态 - 支持
MapReduce - 支持 严格一致性模型
2-Schema And Data Modeling
什么是 一个图的
Schema
每个 JanusGraph 由 Edge Labels , Property Keys, Vertex Labels 组成.
用 关系图谱来举例子.
- 点可以是 用户(User), 笔记(Note), 我们用 Vertex Label 来定义点的类型
- 边可以是 (点赞笔记) (收藏笔记) (关注其他人) , 我们可以用 Edge Label 来定义边的类型
- 而
ProperKey可以同时被点和边复用,用来定义PayLoad, 一个强DataType的PayLoad, 例如 关系的创建时间,例如关系的 创建时间.
边的多重性,规范了这个
Edge允许的链接模式.
MULTI: 默认的, 一对顶点之间可以有多条相同标签的边, 多对多?SIMPLE: 最多一条MANY2ONE: 对任意一个顶点,最多只可以有一条该标签的出边,没有限制入边的数量ONE2MANY:对任意一个顶点,最多只可以有一条该标签的入边,没有限制出边的数量ONE2ONE:对任意一个顶点,最多只可以有一条该标签的入边和出边。
mgmt = graph.openManagement()
follow = mgmt.makeEdgeLabel('follow').multiplicity(MULTI).make()
mother = mgmt.makeEdgeLabel('mother').multiplicity(MANY2ONE).make()
mgmt.commit()
我们创建了属性就可以用在
3-Basic Usage
我们使用 众神关系图来说明这个情况.
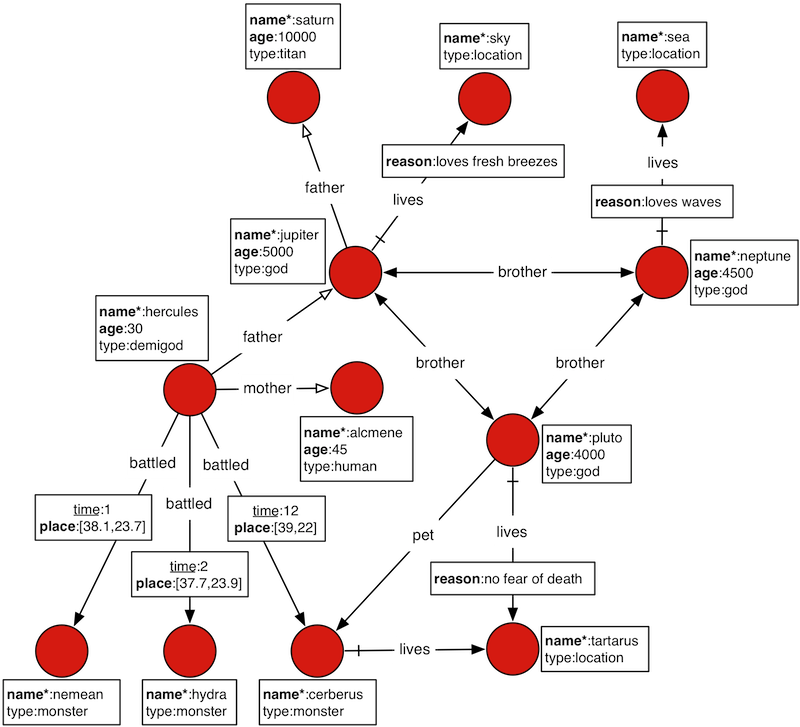
一个基本的 query 小例子的
gremlin> g.V().has('name', 'hercules').out('father').out('father').values('name')
==>saturng: 从当前图开始遍历V(): 寻找顶点has('name', 'hercules'):过滤出名称属性为hercules的顶点(只有一个这样的顶点)out('father'):从Hercules顶点出发,遍历外向的从父亲顶点发出的边。out('father'):从Hercules的父亲的顶点(即Jupiter)出发,遍历外向的从父亲顶点发出的边。values('name'):获取”hercules”顶点的祖父的名称属性
4-QuickStart
准备 schema
graph = JanusGraphFactory.open('conf/janusgraph-inmemory.properties')
mgmt = graph.openManagement()
mgmt.printSchema()
## 1. 边
### 关注边
follow = mgmt.makeEdgeLabel('follow').multiplicity(MULTI).make()
### 收藏边
fav = mgmt.makeEdgeLabel('fav').multiplicity(MULTI).make()
### 点赞边
like=mgmt.makeEdgeLabel('like').multiplicity(MULTI).make()
## 2. 点
userLabel = mgmt.makeVertexLabel('user').make()
noteLabel = mgmt.makeVertexLabel('note').make()
## 3. 属性
### 创建时间
createAt = mgmt.makePropertyKey('createAt').dataType(Long.class).cardinality(Cardinality.SINGLE).make()
### userId
userId = mgmt.makePropertyKey('userId').dataType(String.class).cardinality(Cardinality.SINGLE).make()
### noteId
noteId = mgmt.makePropertyKey('noteId').dataType(String.class).cardinality(Cardinality.SINGLE).make()
## 4. 定义约束, userId 的唯一性 和 noteId 的唯一性
mgmt.buildIndex('byUserIdUnique', Vertex.class).addKey(userId).unique().indexOnly(userLabel).buildCompositeIndex()
mgmt.buildIndex('byNoteIdUnique', Vertex.class).addKey(noteId).unique().indexOnly(noteLabel).buildCompositeIndex()
mgmt.commit()添加数据
## 1. 增加用户
u1 = graph.addVertex(T.label, 'user', 'userId', 'u1')
u2 = graph.addVertex(T.label, 'user', 'userId', 'u2')
u3 = graph.addVertex(T.label, 'user', 'userId', 'u3')
u4 = graph.addVertex(T.label, 'user', 'userId', 'u4')
g = graph.traversal() // 获取一个新的图遍历对象
users = g.V().hasLabel('user').valueMap('userId').toList() // 获取所有 "user" 顶点的 "userId" 属性
## 2. 用户关注用户
u1.addEdge('follow', u2)
u1.addEdge('follow', u3)
u2.addEdge('follow', u4)
g = graph.traversal() // 获取一个新的图遍历对象
g.V().has('user', 'userId', 'u1').out('follow').values('userId').toList()
## 3. 增加笔记
n1 = graph.addVertex(T.label, 'note', 'noteId', 'n1');
n2 = graph.addVertex(T.label, 'note', 'noteId', 'n2');
n3 = graph.addVertex(T.label, 'note', 'noteId', 'n3');
n4 = graph.addVertex(T.label, 'note', 'noteId', 'n4');
## 4. 增加收藏关系
//
u1.addEdge('fav', n1);
u2.addEdge('fav', n1);
u2.addEdge('fav', n2);
u2.addEdge('fav', n3);
u3.addEdge('fav', n3);
u3.addEdge('fav', n4);
graph.tx().commit();简单的2个查询.
## 1. 深度查询
### 思路: 从 u1 出发,找到 u1 关注的人和 二度关注的人 然后 union 起来
g.V().has('user', 'userId', 'u1').union(out('follow'), out('follow').out('follow')).dedup().values('userId').toList()
## 2. 基于 用户的关注关系 给 u1 推荐笔记
### 思路:
### 1. 找到用户关注的人
### 2. 查询这些人收藏的笔记
g.V().has('user', 'userId', 'u1').out('follow').out('fav').toList()