Refer
1-概述
Netflix Java 团队在 使用 jDK21 的时候遇到了坑.
1) 问题表现
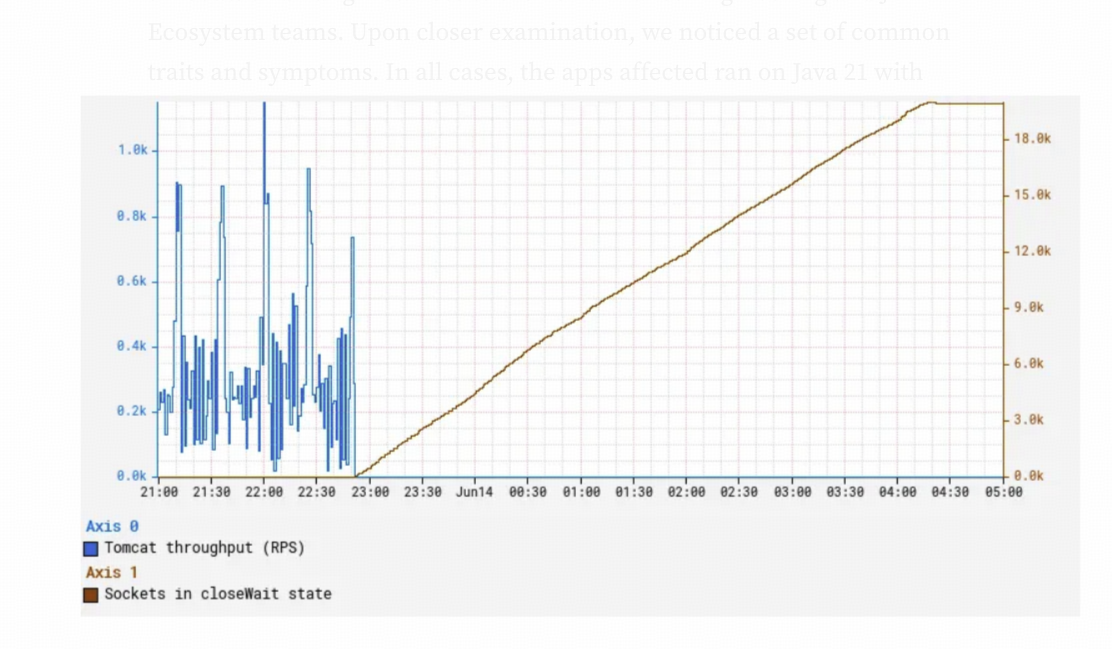
JVM进程Hang死, 假死 ;- 导致了 间歇性的超时 和 实例挂起 ;
closeWait状态的Socket持续性增加不减少 ;
2) 排查发现的共同点
- 都是
JDK21+SpringBoot3+Tomcat embed的场景
Tips
回忆一下 CLOSED_WAIT 状态, 主动方(这里是客户端)发起方发起
FIN请求,被动方(这里是服务端) 接收到之后,发送ACK确认这个FIN, 然后服务端进入CLOSE_WAIT状态, 这个时候应该去处理释放掉资源. 然后再发送FIN给客户端 …
- 第一感觉是 什么东西导致 连接没有办法正常
CLOSED, 然后不发送FIN, 一直卡死在CLOSED_WAIT.
2-定位
1) jstack 看见的大多数线程都是空闲的
使用 jstack 看见的线程都是 空闲状态和实际中的场景不符合. 然后意识到 jstack 看不到虚拟线程的问题,改用命令 jcmd Thread.dump_to_file 去包含虚拟线程的状态.
2) 分析 线程 dump.
#119821 "" virtual
#119820 "" virtual
#119823 "" virtual
#120847 "" virtual
#119822 "" virtual
...有数千个虚拟线程但是是 “blank” 的状态. 这些个线程的数目和 ClosedWait 的数目相同, 这就基本定位问题了. 为什么是 blank,因为这些个对象创建了,但是一直没有 started , 所以 stack trace 是空的
3) 虚拟线程 VT 的基本原理
VT不是1:1映射到OS-Level的线程VT可以看做是调度到fork-join-thread-pool中的任务- 当一个
VT进入block的时候, 例如等待Future的时候,就会释放掉占用的OS线程, 并在内存中等待到可以恢复. OS线程可以被重新分配给同一个fork-join池子中的其他VT- 这允许大量的
VT去复用少量的OS-Thread, 在JVM的文档中称为Carrier-Thread
4) Tomcat 使用 VT 的原理
Tomcat 创建 VT 的源码 ,对于源码的基本解释如下:
Tomcat会给每个Request创建VT- 如果这个时候没有可用的
OS线程来mount, 就会出于上面我们观察的状态. - 所以可能的问题是
OS线程资源耗尽?
**5) 为什么之前的 VT 会钉在(pinned) 底层的 OS-Thread 中 **
- 这是一个已知问题,不能在虚拟线程中使用
synchronized. - 否则,虚拟线程会无法释放掉底层的
OS-Thread, 类似之前的行为,阻塞了整个底层的OS-Thread.
推荐的方法是:
synchronized(lockObj) {
frequentIO();
}改为
lock.lock();
try {
frequentIO();
} finally {
lock.unlock();
}6) 回到tomcat 的问题
#119515 "" virtual
java.base/jdk.internal.misc.Unsafe.park(Native Method)
java.base/java.lang.VirtualThread.parkOnCarrierThread(VirtualThread.java:661)
java.base/java.lang.VirtualThread.park(VirtualThread.java:593)
java.base/java.lang.System$2.parkVirtualThread(System.java:2643)
java.base/jdk.internal.misc.VirtualThreads.park(VirtualThreads.java:54)
java.base/java.util.concurrent.locks.LockSupport.park(LockSupport.java:219)
java.base/java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:754)
java.base/java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:990)
java.base/java.util.concurrent.locks.ReentrantLock$Sync.lock(ReentrantLock.java:153)
java.base/java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:322)
zipkin2.reporter.internal.CountBoundedQueue.offer(CountBoundedQueue.java:54)
zipkin2.reporter.internal.AsyncReporter$BoundedAsyncReporter.report(AsyncReporter.java:230)
zipkin2.reporter.brave.AsyncZipkinSpanHandler.end(AsyncZipkinSpanHandler.java:214)
brave.internal.handler.NoopAwareSpanHandler$CompositeSpanHandler.end(NoopAwareSpanHandler.java:98)
brave.internal.handler.NoopAwareSpanHandler.end(NoopAwareSpanHandler.java:48)
brave.internal.recorder.PendingSpans.finish(PendingSpans.java:116)
brave.RealSpan.finish(RealSpan.java:134)
brave.RealSpan.finish(RealSpan.java:129)
io.micrometer.tracing.brave.bridge.BraveSpan.end(BraveSpan.java:117)
io.micrometer.tracing.annotation.AbstractMethodInvocationProcessor.after(AbstractMethodInvocationProcessor.java:67)
io.micrometer.tracing.annotation.ImperativeMethodInvocationProcessor.proceedUnderSynchronousSpan(ImperativeMethodInvocationProcessor.java:98)
io.micrometer.tracing.annotation.ImperativeMethodInvocationProcessor.process(ImperativeMethodInvocationProcessor.java:73)
io.micrometer.tracing.annotation.SpanAspect.newSpanMethod(SpanAspect.java:59)
java.base/jdk.internal.reflect.DirectMethodHandleAccessor.invoke(DirectMethodHandleAccessor.java:103)
java.base/java.lang.reflect.Method.invoke(Method.java:580)
org.springframework.aop.aspectj.AbstractAspectJAdvice.invokeAdviceMethodWithGivenArgs(AbstractAspectJAdvice.java:637)
...
在 brave.RealSpan.finish 方法中虚拟线程被 Pined 了 .
为什么我们认为是 pined. 因为从源码上来看. 在 RealSpan-134行 使用了 synchronized 表明是定住的.
@Override public void finish(long timestamp) {
synchronized (state) {
pendingSpans.finish(context, timestamp);
}
}- 为什么是 4个? 看
jdk的 虚拟线程VirtualThread源码 说明了问题. 因为虚拟机上只有4个 VCPU - 我们总结一下上面的
stack, 来了4个请求,每个请求,Tomcat会让他进入这个方法, 这个方法最外层是一个synchronized, 里面的方法又调用了CountBoundedQueue.offer -> ReentrantLock.lock, 需要等待某一个锁的释放,而这个锁又卡住了,所以大家一起挂了.
7) 4个虚拟线程以为 同步+锁的循环调用卡死了,这个被卡住的 Lock 是啥? 没办法
Tips
通常的情况, Java 的线程转储技术会显示 锁的持有者, 类似
- locked <0x…> (at …)或者Locked ownable synchronizers, 但是虚拟线程中 缺失了这些信息. 这是JDK21的缺失工作
还有剩下的2个 thread 在等待相同的 ReentrantLock 和关联的 Condition.
第5个.
#119516 "" virtual
java.base/java.lang.VirtualThread.park(VirtualThread.java:582)
java.base/java.lang.System$2.parkVirtualThread(System.java:2643)
java.base/jdk.internal.misc.VirtualThreads.park(VirtualThreads.java:54)
java.base/java.util.concurrent.locks.LockSupport.park(LockSupport.java:219)
java.base/java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:754)
java.base/java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:990)
java.base/java.util.concurrent.locks.ReentrantLock$Sync.lock(ReentrantLock.java:153)
java.base/java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:322)
zipkin2.reporter.internal.CountBoundedQueue.offer(CountBoundedQueue.java:54)
zipkin2.reporter.internal.AsyncReporter$BoundedAsyncReporter.report(AsyncReporter.java:230)
zipkin2.reporter.brave.AsyncZipkinSpanHandler.end(AsyncZipkinSpanHandler.java:214)
brave.internal.handler.NoopAwareSpanHandler$CompositeSpanHandler.end(NoopAwareSpanHandler.java:98)
brave.internal.handler.NoopAwareSpanHandler.end(NoopAwareSpanHandler.java:48)
brave.internal.recorder.PendingSpans.finish(PendingSpans.java:116)
brave.RealScopedSpan.finish(RealScopedSpan.java:64)
...- 也是个虚拟线程
- 尝试完成一个
Span,brave.RealScopedSpan.finish(RealScopedSpan.java:64)
第6个是一个 正常的线程.
#107 "AsyncReporter <redacted>"
java.base/jdk.internal.misc.Unsafe.park(Native Method)
java.base/java.util.concurrent.locks.LockSupport.park(LockSupport.java:221)
java.base/java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:754)
java.base/java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:1761)
zipkin2.reporter.internal.CountBoundedQueue.drainTo(CountBoundedQueue.java:81)
zipkin2.reporter.internal.AsyncReporter$BoundedAsyncReporter.flush(AsyncReporter.java:241)
zipkin2.reporter.internal.AsyncReporter$Flusher.run(AsyncReporter.java:352)
java.base/java.lang.Thread.run(Thread.java:1583)进入 方法源码
/** Blocks for up to nanosTimeout for spans to appear. Then, consume as many as possible. */
@Override int drainTo(SpanWithSizeConsumer<S> consumer, long nanosTimeout) {
try {
// This may be called by multiple threads. If one is holding a lock, another is waiting. We
// use lockInterruptibly to ensure the one waiting can be interrupted.
lock.lockInterruptibly();
try {
long nanosLeft = nanosTimeout;
while (count == 0) {
if (nanosLeft <= 0) return 0;
nanosLeft = available.awaitNanos(nanosLeft);
}
return doDrain(consumer);
} finally {
lock.unlock();
}
} catch (InterruptedException e) {
return 0;
} finally {
// record after draining reduces the amount of gauge events vs on doing this on report
metrics.updateQueuedSpans(count);
}
}- 调用链 ,
drainTo -> awaitNanos -> park.
方法很正常,使用的也是 lock.
| Thread ID/name | Virtual? | “synchronized” block? | Pinned? | Waiting for the lock? |
|---|---|---|---|---|
| #119513 "" | Yes | Yes | Yes | Yes |
| #119514 "" | Yes | Yes | Yes | Yes |
| #119515 "" | Yes | Yes | Yes | Yes |
| #119517 “<redacted> @DefaultExecutor - 46542” | Yes | Yes | Yes | Yes |
| #119516 "" | Yes | No | No | Yes |
| #107 “AsyncReporter | No | No | N/A | Yes |
但是这个线程进入的时候拥有锁, 然后 await进入睡眠, 然后被唤醒的时候是没有锁的 .
8) 缺乏工具,直接上大招 ,mat 直接分析 Lock 对象的状态

state = 0, 代表锁没有被持有exclusiveOwnerThread是null, 说明没有对象能拥有这把锁AQS中的head对象waiter = null && status = 0head的next中有一个waiter != null, 指向到正在竞争锁的虚拟线程 119516.
我们用比喻的方法,来说明这个问题. 想象一个带锁的房间和一系列要进入的人.
- 初始状态: 锁开的,房间门打开了,也就是说
state = 0, 然后exclusiveOwnerThread = null - 第一个人,head 站在门口, 后面的哥们就是 next, 也就是
#119516
9) 所以上面的状态是 head 释放了锁,并告诉 next 你可以进去了,但是 next 卡住了,他就站在门口,他不进去,介于被告知 你可以进去了的状态 和 进去的中间状态, 这得看源码了
@ReservedStackAccess
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (getExclusiveOwnerThread() != Thread.currentThread())
throw new IllegalMonitorStateException();
boolean free = (c == 0);
if (free)
setExclusiveOwnerThread(null);
setState(c);
return free;
}
- 通过这个源码我们能理解如何 释放锁,也就是开门的过程.
setExclusiveOwnerThread(null)setState(0)- 然后通知下一个哥们,说你可以进去了,会发出信号
- 这个时候
head还是当前的哥们,符合mat的观察.
下面分析 accquire 的源码. 很恶心,其实是下面的伪代码,死循环即可.
while(true) {
// 门开着可以进去
if (tryAcquire()) {
return; // lock acquired
}
park();
}这里就是 next 的逻辑了,你该进去了,你为啥不进去.
其实分析到这里,联系上下文猜一下,应该这个被告知的哥们 next 是一个虚拟线程,但是当前没有资源给你调度,你就卡住了,一种有趣的死锁状态,虚拟线程又进一步增加了死锁的可能性.
10) 总结一下, 上面的情况
一个有4个座位的房间(4个 VCPU ). 房间有一把锁
- 4个虚拟线程(VT)坐在座位上,它们都在等待获取锁。这些是那些被”钉住”(pinned)的VT,它们在synchronized块内等待锁。
- 第5个VT(#119516)是刚被告知可以获取锁的线程。它有”钥匙”(被通知可以获取锁),但没有座位(OS线程)来执行获取锁的操作。
- 第6个是平台线程,它可以独立于座位(OS线程)运行,但也在等待获取锁。
妙在 有钥匙的 老5 没有资源(座位) 给他开锁,于是这个状态卡死了.
3-复现
在理解原理之后,可以用如下代码随时复现这个 bug.
import java.time.Duration;
import java.util.List;
import java.util.concurrent.locks.ReentrantLock;
import java.util.stream.IntStream;
import java.util.stream.Stream;
/**
* Demonstrate potential for deadlock on a {@link ReentrantLock} when there is both a synchronized and
* non-synchronized path to that lock, which can allow a virtual thread to hold the lock, but
* other pinned waiters to consume all the available workers.
*/
public class VirtualThreadReentrantLockDeadlock {
public static void main(String[] args) {
final boolean shouldPin = args.length == 0 || Boolean.parseBoolean(args[0]);
final ReentrantLock lock = new ReentrantLock(true); // With faireness to ensure that the unpinned thread is next in line
lock.lock();
Runnable takeLock = () -> {
try {
System.out.println(Thread.currentThread() + " waiting for lock");
lock.lock();
System.out.println(Thread.currentThread() + " took lock");
} finally {
lock.unlock();
System.out.println(Thread.currentThread() + " released lock");
}
};
// 1. 先启动 unpinned, 这个时候去尝试获取锁,失败! 虚拟线程,没有 sync,就直接释放掉底层的资源
Thread unpinnedThread = Thread.ofVirtual().name("unpinned").start(takeLock);
// 2. 再依次启动 pinned.也去尝试获取锁失败,但是因为 sync,导致了 pinned
List<Thread> pinnedThreads = IntStream.range(0, Runtime.getRuntime().availableProcessors())
.mapToObj(i -> Thread.ofVirtual().name("pinning-" + i).start(() -> {
if (shouldPin) {
// synchronized 的 对象不同,所以这里不会卡
synchronized (new Object()) {
// 这里的 lock 是同一把
takeLock.run();
}
} else {
takeLock.run();
}
})).toList();
// 3. 释放锁, 由于是公平锁,先进先出,应该能保证 是 unpined 获取到锁,但是他没有底层资源去执行了
lock.unlock();
Stream.concat(Stream.of(unpinnedThread), pinnedThreads.stream()).forEach(thread -> {
try {
if (!thread.join(Duration.ofSeconds(3))) {
throw new RuntimeException("Deadlock detected");
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
}
}
我们解释一下这个代码:
ReentrantLock:用于模拟我们讨论的锁。- 一个未钉住的虚拟线程(
unpinnedThread) - 多个可能被钉住的虚拟线程(
pinnedThreads)
核心就是让 那个没有定住的虚拟线程拥有 lock,但是又没有资源给你调度 ~ .疑问是公平锁能绝对保证顺序吗?