1-理解 Pod
1-1 关键字段
1) 最小的编排单元
不选择容器作为编排单元,更接近一个 虚拟的机器的概念.
比如说, Pod 的网络定义 机器的 网卡, Pod 的 Storage 定义了机器的磁盘. 凡是跟容器的 Namespace 有关的概念,都是在 Pod 级别定义的. Pod 中的容器可以共享这些 Namespace
2) NodeSelector
把 Node 和 Pod 绑定的方式.
apiVersion: v1
kind: Pod
...
spec:
nodeSelector:
disktype: ssd3) NodeName
这个值一旦被赋值了,则代表已经经过了 调度. 一个 Deployment 如果 replica > 1 则会生成多个 Pod.
其中的每个 Pod 经过了调度则会分配到某一个 Node 上. 所以上面的字段一般调试的时候有用,我们手动写一个 NodeName , 可以欺骗 k8s 说已经经过了调度.
4) HostAliases : 定义 /etc/hosts
apiVersion: v1
kind: Pod
...
spec:
hostAliases:
- ip: "10.1.2.3"
hostnames:
- "foo.remote"
- "bar.remote"
...5) Namespace 定义
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
hostNetwork: true
hostIPC: true
hostPID: true
containers:
- name: nginx
image: nginx
- name: shell
image: busybox
stdin: true
tty: true6) 容器的关键字段
ImagePullPolicy: 关键lifecycle: 容器的钩子函数
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"]1-2 生命周期
Pending: 这个状态说明 ,Pod的Yaml已经提交给了K8s,Api对象已经创建了并且保存在etcd中, 但是因为某种原因,有些容器无法创建成功Running: 所有的容器都创建成功了,并且至少有一个正在运行中Succeeded: 所有的容器都运行完毕Failed: 这个状态下,Pod 里至少有一个容器以不正常的状态(非 0 的返回码)退出。这个状态的出现,意味着你得想办法 Debug 这个容器的应用,比如查看 Pod 的 Events 和日志。Unknown: 这是一个异常状态,意味着 Pod 的状态不能持续地被 kubelet 汇报给 kube-apiserver,这很有可能是主从节点(Master 和 Kubelet)间的通信出现了问题。
2-理解 service
2-1 Service 类型
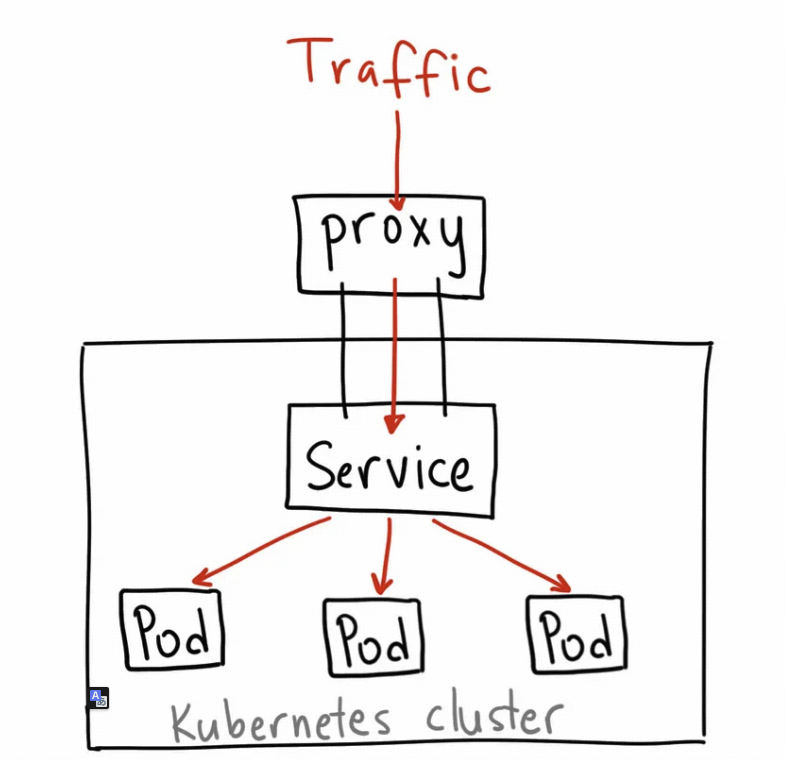
1) ClusterIP
apiVersion: v1
kind: Service
metadata:
name: my-internal-service
spec:
selector:
app: my-app
type: ClusterIP
ports:
- name: http
port: 80
targetPort: 80
protocol: TCP- 给一个 稳定的
IP, 适合用来测试. - 不能通过
k8s外直接访问, 需要利用类似kube forward或者kube proxy的方案来解决:http://localhost:8080/api/v1/proxy/namespaces/<NAMESPACE>/services/<SERVICE-NAME>:<PORT-NAME>/
2) NodePort
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service
spec:
selector:
app: my-app
type: NodePort
ports:
- name: http
port: 80
targetPort: 80
nodePort: 30036
protocol: TCP- 可以看出来多了一个
NodePort, 每个Node上都会启动这个Port, 然后把到这个Port的流量转发到对应的Service - 有一些约束:
- You can only have one service per port
- You can only use ports
30000-32767 - If your Node/VM ip address change, you need to deal with that
3) LoadBalancer
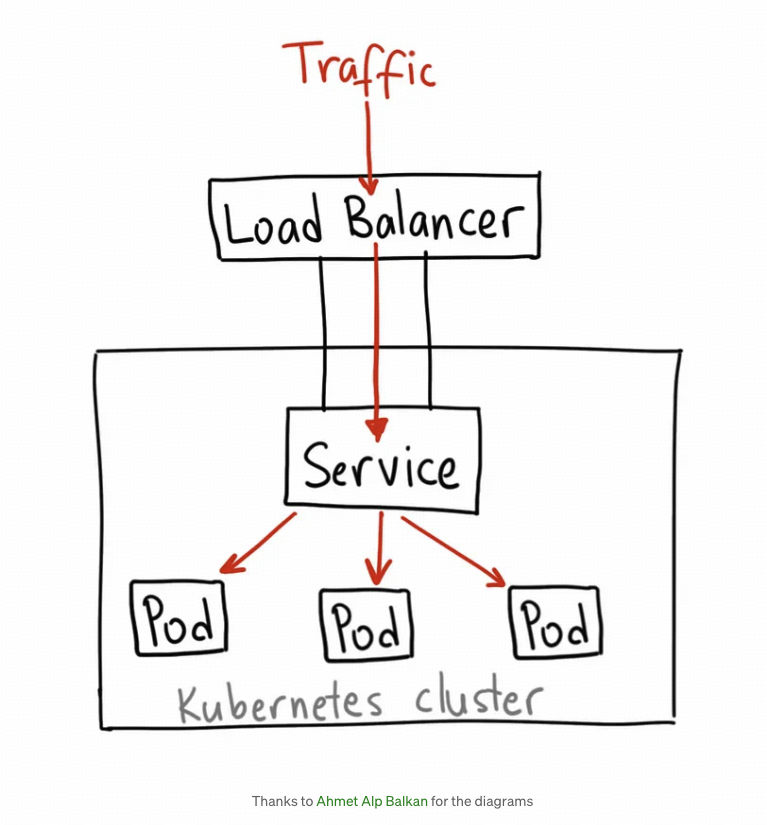
- 是最直接暴漏
Service的方法, 提供一个稳定的ip和负载均衡功能. - 没有任何的
filtering,routing能力. 同时也意味着基本支持所有的协议,HTTP,TCP,UDP,Websockets,GRPC… - 如果是云上,一般这个
service的ip是由 云厂商分配的. - 缺点也很明显,service 数目会增加,而且每个 service 是单独分配的 ip,成本昂贵
apiVersion: v1
kind: Service
metadata:
name: my-internal-knative-gateway
namespace: istio-system
labels:
app.kubernetes.io/component: net-istio
app.kubernetes.io/name: knative-serving
app.kubernetes.io/version: 1.12.3
experimental.istio.io/disable-gateway-port-translation: 'true'
networking.knative.dev/ingress-provider: istio
annotations:
service.beta.kubernetes.io/cce-blb-type: appblb # 保留这个注解,如果需要特定的负载均衡器类型
service.beta.kubernetes.io/cce-load-balancer-internal-vpc: "true" # 这个注解使负载均衡器成为内部的
spec:
type: LoadBalancer
ports:
- name: http2
port: 8081
protocol: TCP
targetPort: 8081
selector:
app: cluster-local-gateway
istio: cluster-local-gateway
sessionAffinity: None
externalTrafficPolicy: ClusterTips
ServiceIp 比较稳定,但是也是有可能会变化的. 比如删除重建,手动释放,基本不会出现, 如果追求稳定,可以用云厂商提供的 静态ip 能力
3-理解 Controller Pattern
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80在 k8s control-plane 中有一个组件叫做, kube-controller-manager, 他是一系列控制器的集合.
$ cd kubernetes/pkg/controller/
$ ls -d */
deployment/ job/ podautoscaler/
cloud/ disruption/ namespace/
replicaset/ serviceaccount/ volume/
cronjob/ garbagecollector/ nodelifecycle/ replication/ statefulset/ daemon/
...伪代码逻辑如下:
for {
实际状态 := 获取集群中对象X的实际状态(Actual State)
期望状态 := 获取集群中对象X的期望状态(Desired State)
if 实际状态 == 期望状态{
什么都不做
} else {
执行编排动作,将实际状态调整为期望状态
}
}
滚动更新实际上是 ReplicaSet 对象的能力, Deployment 仅仅在 ReplicaSet 的基础上,添加了 UP-TO-DATE 跟版本相关的状态字段.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
...
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 14-理解 Storage
4-1 PV 和 PVC
PV: 描述的是一个持久化的数据卷. 一般由运维直接创建PVC:Pod希望的持久化存储的属性, 例如Volume存储的大小, 可读写权限等等, 一般由开发人员创建 或者作为一个 模版自动化.
用户创建的 PVC 要真正的被容器使用起来, 必须和某个符合条件的 PV 进行绑定.
PV和PVC的spec字段,比如大小要满足要求storageClassName必须一致.
当然也可以直接制定 volumeName .
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs
spec:
capacity:
storage: 14000Gi
accessModes:
- ReadWriteMany
nfs:
server: 10.1.1.2
path: "/opt/data"
mountOptions:
- hard
- nfsvers=4.1
- noatime
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-claim
namespace: example-namespace
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
resources:
requests:
storage: 14000Gi
volumeName: nfs可以把 PVC 和 PV 理解为面向对象中 接口和实现的关系, PVC 定义的是开发想要啥存储.
Tips
同样的, PersistentVolumeController 控制器组件会不断地去做
PV和PVC的绑定工作
4-2 PV 和 持久化存储
持久化的存储是 是这个存储不会和容器的生命周期绑定,容器删除了,存储也在,同时要求是不和 宿主机绑定的,只有某个宿主机上容器才能使用。 下面2个都不满足要求
hostpath: 需要访问宿主机文件的场景.empthDir: 提供了一个临时的空目录给 容器使用, 适合Pod内部去共享数据, 在Pod删除之后会直接消失
一般持久化的卷都 依赖于远程的存储服务. 而 k8s 的工作则是把这些存储服务注入到 容器中, 一般分为2个阶段:
Attach: 给Pod创建Volume目录,默认路径是:/var/lib/kubelet/pods/<pod-id>/volumes/kubernetes.io~<volume-type>/, 由AttachDetachController负责
# 通过lsblk命令获取磁盘设备ID
$ sudo lsblk
# 格式化成ext4格式
$ sudo mkfs.ext4 -m 0 -F -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/<磁盘设备ID>
# 挂载到挂载点
$ sudo mkdir -p /var/lib/kubelet/pods/<Pod的ID>/volumes/kubernetes.io~<Volume类型>/<Volume名字>Mount: 磁盘设备格式化然后挂载到Volume在的宿主机, 由VolumeManagerReconcier负责. 这个是kubelet的一部分.
$ mount -t nfs <NFS服务器地址>:/ /var/lib/kubelet/pods/<Pod的ID>/volumes/kubernetes.io~<Volume类型>/<Volume名字> Tips
上面把2个步骤解耦, 第一个步骤比较耗时,而且如果是
nfs可以跳过, 第二个步骤是简单的mount, 直接放到kubelet主循环中,sync loop,VolumeManagerReconcier是 一个独立的Goroutine, 在kubelet的设计中,绝对不允许任何的block操作.
4-3 理解 StorageClass
1) Dynamic Provisioning
一个大规模的 Kubernetes 集群里很可能有成千上万个 PVC,这就意味着运维人员必须得事先创建出成千上万个 PV。更麻烦的是,随着新的 PVC 不断被提交,运维人员就不得不继续添加新的、能满足条件的 PV,否则新的 Pod 就会因为 PVC 绑定不到 PV 而失败。在实际操作中,这几乎没办法靠人工做到。
而 Dynamic Provisioning 则是自动创建 PV 的机制可以解决这个问题.
2) StorageClass
是 Dynamic Provisioning 的核心. 他会定义2个部分的内容.
PV的属性, 例如存储类型,Volume的大小等等- 创建这种
PV需要的插件. 例如Ceph.
然后通过 StorageClass 的方式去自动绑定 实现动态化,用 Rook 作为例子.
apiVersion: ceph.rook.io/v1beta1
kind: Pool
metadata:
name: replicapool
namespace: rook-ceph
spec:
replicated:
size: 3
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: block-service
provisioner: ceph.rook.io/block
parameters:
pool: replicapool
#The value of "clusterNamespace" MUST be the same as the one in which your rook cluster exist
clusterNamespace: rook-ceph开发者只需要用 storageClass 表明他希望使用哪种类型的存储设备即可.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: claim1
spec:
accessModes:
- ReadWriteOnce
storageClassName: block-service
resources:
requests:
storage: 30Gi- 然后
k8s会 自动帮我们创建一个pv. 这个就是动态的核心.
但是, storageClass 不是专门 为动态绑定的设计, 主要用于定义存储的类型和参数.
5-理解网络
5-1 理解 docker 中的网桥
1) 理解 docker 中的网桥
在一个 IDC 内,组网的方式一般是 一个交换机连接多个物理机, 交换机会维护 MAC 地址 和 ip 地址的关系. 一根网线连接物理机和交换机的一个口.
在 Linux 中能起到 虚拟交换机 作用的是 bridge, 可以根据 MAC 地址学习把数据包如何转发到不同的端口.
Docker 默认会在宿主机上创建一个 docker0 的网桥, 然后通过 虚拟设备 Veth Pair 作为虚拟的网线, Veth Pair 核心就是一个 虚拟网卡对,这一对虚拟网卡中从一个网卡发出的数据包,会直接出现在另一张网卡. 哪怕 2个网卡在不同的 Namespace 中. 所以他的作用是 网线
Docker 中容器内部:
eth0就是veth-pair的一端, 同时也是容器内部默认的 路由设备, 通过route可以验证 .- 另一端则在宿主机上. 一般叫
veth...., 通过brctl可以发现他插在docker0网桥上,这个虚拟交换机.
2) docker 容器互通
我们再来梳理一下. 假设有2个容器 nginx-1 和 nginx-2 .
$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0要 ping 172.17.0.3 也就是 nginx-2 的时候.
这个网段符合路由规则中第二条, 目标地址是 172.17.0.0/24 ,网关是 0.0.0.0 . 这个直接通过 Iface eth0 直连. 通过二层的网络 直连目标主机.
要能发到目标主机,需要通过 arp 知道他的 mac 地址, 这就是虚拟网桥的租用了, 当一个虚拟网卡对, veth-pair 插到网桥的时候, 会降级为 虚拟交换机的端口. 因此发送 arp 请求的时候, 这个请求会直接出现在 网卡对的另一端, 于是被 网桥接管广播到所有的接口(虚拟网卡) 上, 就能返回 对应的 mac 地址.
有了 mac 地址, 网络就通了.
Tips
上面都是虚拟设备,依赖于
Linux内核,Netfilter能力. 可以在宿主机上看见日志
# 在宿主机上执行
$ iptables -t raw -A OUTPUT -p icmp -j TRACE
$ iptables -t raw -A PREROUTING -p icmp -j TRACE可以在 syslog 中看见数据包日志.
所以是:
host1-容器1 → host1-网桥 → host1-容器2 这样的逻辑
3) docker 连通宿主机
一样的,当容器视图连接 另一个宿主机的东西,必须先到 另一台宿主机的网卡, 例如 ping 10.168.0.3 , 容器内部发的数据会路由到 网桥, 网桥的另一端本身就是通 宿主机的 namespace , 通过宿主机 本身的路由规则 就能找到另外的宿主机.
host1-容器1 → host1-网桥 → host2-宿主机
4) 集群 overlay
本质一样的,就是在已有的宿主机网络上, 通过软件 构建一个覆盖在宿主机网络上,可以把多个容器 连在一起的 虚拟网络, 称为 Overlay 覆盖网络技术
实现的方式就太多了. 比如可以在 宿主机搞个特殊的网桥,然后组网为. 或者不需要网桥,只要通过某个方法能去 修改宿主机的路由表配置 等等.
5-2 理解 flannel
最开始 k8s 网络插件, 他是一个框架,有3种实现.
VXLANhost-gwUDP
1) UDP
最早实现,最简单,性能最差,已经被废弃.
- 宿主机 Node 1 上有一个容器 container-1,它的 IP 地址是 100.96.1.2,对应的 docker0 网桥的地址是:100.96.1.1/24。
- 宿主机 Node 2 上有一个容器 container-2,它的 IP 地址是 100.96.2.3,对应的 docker0 网桥的地址是:100.96.2.1/24。
container1 要连接 container2 .
- 源地址是
100.96.1.2, 目标地址是100.96.2.3 - 目标地址不在宿主机的网桥中, 会走默认网关,
route可查. 这个意味着 会通过容器的网关交给 docker0 网桥 - 宿主机的网桥怎么做呢,这个就 取决于宿主机自己的路由规则. 而
Flannel会自动在 宿主机中创建路由规则, 参考如下命令, 会进入到 第二条规则,也就是一个 flannel0 的虚拟设备
# 在Node 1上
$ ip route
default via 10.168.0.1 dev eth0
100.96.0.0/16 dev flannel0 proto kernel scope link src 100.96.1.0
100.96.1.0/24 dev docker0 proto kernel scope link src 100.96.1.1
10.168.0.0/24 dev eth0 proto kernel scope link src 10.168.0.2flannel0这个设备是一个Tunnel设备,这意味着 他工作在 L3, 也就是IP这一层. 可以解析并且根据 ip 传递报文. 其本质上是收到了这个报文,需要从 内核 向用户态进程 Flannel 传递报文.flanneld也就是用户态进程收到了报文, 就可以直接请求 给Node2的宿主机. 因为 这个时候每个宿主机代表一个子网,他的网段区间和宿主的关系 会被持久化到etcd中.flanneld会去查, 所以可以发给对应的 宿主机
$ etcdctl get /coreos.com/network/subnets/100.96.2.0-24
{"PublicIP":"10.168.0.3"}- 比较神奇的是
flannel0会把这个IP包封装为一个UDP然后发送给Node2的8285端口, 然后到了Node2, 会从UDP中还原出来. 根据里面的 dest 地址转发给Node2的flannel0设备 - …
测试也比较简单, Docker 启动的时候可以已 指定子网.
$ FLANNEL_SUBNET=100.96.1.1/24
$ dockerd --bip=$FLANNEL_SUBNET ...
相比于两台宿主机之间的直接通信,基于 Flannel UDP 模式的容器通信多了一个额外的步骤,即 flanneld 的处理过程。而这个过程,由于使用到了 flannel0 这个 TUN 设备,仅在发出 IP 包的过程中,就需要经过三次用户态与内核态之间的数据拷贝,如下所示:

- 容器进程是用户态,要通过
docker0进入内核态 IP包根据route规则进入了TUNflannel0设备,回到了 用户态的flanneld进程flanneld封装为UDP重新进入内核态,通过宿主机的eth0发出去
本质上就一句话,借助了 用户态的 flanneld 进程就是原罪.
2)-VXLAN 技术
虚拟可扩展局域网技术: VXLAN . 是 Linux 内核本身就支持的一种网络虚拟化技术. VXLAN 可以在 内核态实现上述封装和解封的工作.

核心想法: 在现有的三层网路上,覆盖 一层虚拟的,由内核 VXLAN 模块维护的二层网络, 他可以让在这个 二层网络上的所有 “主机”, 不管是虚拟机 还是宿主机, 都可以像在 LAN 一样通信.
VXLAN会在宿主机 上设置一个特殊的网络设备 作为 “隧道” 的2端. 这个设备叫做,VTEP: VXLAN Tunnel End PointVTEP的职责和flanneld进程一样, 只是这里封装的不是 三层的IP报文,而是二层的数据帧- 其核心在于所有的工作 都在内核中完成,不需要额外的数据拷贝
过程和上面类似,报文会通过 docker0 网桥到 flannel.1 设备上处理,也就是 隧道的 入口.
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
...
10.1.16.0 10.1.16.0 255.255.255.0 UG 0 0 0 flannel.1宿主机上都有这样一条路由规则, 凡事要去 10.1.16.0/24 的报文,都要通过 flannel.1 设备发出,最后要去的网关的地址是 10.1.16.0. 这个网关地址代表的是 物理机上的 VTEP 设备.
同样有了 IP, 要解决的就是 交换机的 ARP 能力问题.
在 node2 启动的死后, flanneld 进程就会自动在. Node1 上添加记录.
# 在Node 1上
$ ip neigh show dev flannel.1
10.1.16.0 lladdr 5e:f8:4f:00:e3:37 PERMANENT
比较奇怪哈,mac 地址都应该的 ip 都是一样的. 其实内部还有一个 FDB 转发数据库.
# 在Node 1上,使用“目的VTEP设备”的MAC地址进行查询
$ bridge fdb show flannel.1 | grep 5e:f8:4f:00:e3:37
5e:f8:4f:00:e3:37 dev flannel.1 dst 10.168.0.3 self permanent同样的,宿主机会包装为一个 UDP 报文.比较特殊, 有一个 VXLAN 头, ip 是 node2 的 ip, mac 是 5e:f8:4f:00:e3:37 就能成功到 node-2 ,Node2 发现有特殊的头 VXLAN-Header 而且 VNI=1, 就会交给设备 flannel.1 , 然后他取出 原始的报文 交给网桥就到了 container2