1-Intro
What is DBlog In Netflix.
- Netflix 的
DBLog是为了统一解决CDC而抽出来的中间层
Tips
CDC: Change-Data-Capture. 非常适合 CQRS 架构的技术
- 目前已经有许多的开源框架 很友好的支持了
CDC, 但是DBLog还是集中的解决了一些问题.
Dblog 的一些主要功能:
- 有序的处理
CDC-Events, 这个是 刚需, 但是各种底层引擎对于顺序的定义又是完全不同的, 例如 Mysql V5 协议中Row-Based和Global-TransactionalId的选择, 很多公司要求实现 统一在 业务方实现一个 精确度高的UpdateAt字段,按照这个排序 ; - 可以在任何的时候进行
Dumps, 个人认为这个是.Optional的, 以Mysql为例子, 一般都有主从集群,Dump大表这样的操作,我们一般是在单独的离线服务器上做的,不一定非要在一层做, 当然如果DBlog原生支持Dump还是很好的 - 把
CDC-log-event事件很快照事件按照Chunk的方式交织处理, 设计的目的是为了 如果进程重启不用重头开始 快照 - 不会使用任何的
Table级别的Lock, 去影响当前Table的写操作 - 解耦出
Output, 可以是一个Stream,DataStore或者Api这种. 这里的Stream是指Kafka,Sqs这种 - 支持
HA
基于之前
Netflix的Delta
Delta更像一个 中间的数据同步组件, 比如从Mysql→ElasticSearch中同步数据组件.
DbLog 是对 Delta 的一个补充
- 获取一个
Source的Full State, 我理解就是Dump这样的功能 - 面向失败的设计, 要求在数据不一致的时候,自动化能进行一个修复,例如 直接基于原来的
Source进行一个Schema→Table→Primary Key级别的修复 - 补上
H-A,Health CHeck这种设计, 例如在 定义一个异常行为是 30min 还没有进行任何数据同步, 这个值应该是可配置的,因为确实有很多历史的Db可能1年都没有新数据 ; - 降低对
Source的影响: 尤其是Dump是一定会有冲击的,至少要不影响写操作,读没办法,一定有点影响, 一个选择 就是 底层选择要选择无锁的方案,不要使用Table Lock, 比如说使用InnodbMysql的工具或者maxwell这种的组件去做 - 优先支持关系型数据库,
Netflix同时使用Mysql和PostGreSql
Existed-Solutions: 当前已经存在的方案
目前的开源框架 无法解决如下问题:
- 如果开始
Dump全库的行为,Cdc Stream可能会有大量的延迟,这个对业务上是无法接受的,非常大的主从延迟 - 大多数方案仅仅支持在 第一次
init的时候触发快照做全量的数据同步,而不是随时可以 触发这个行为,进行补偿和修复 - 有些方案需要
Locking Tables, 甚至PostGreSql的一些开源实现中要求当前的库必须拥有Master的身份 - 大多数方案用了一些
Database specific features: 例如Mysql的Blackhole引擎和Pg的Consistence Snapshot
Tips
这里说明
Netflix对工程工艺的要求确实比较高,例如 最好不要用特殊的引擎, 而是在这一层 解决问题的要求 会带来比较高的成本,但是还是选择去做, 有如下的 选择:
- interleaves log with dump events so that both can make progress
- allows to trigger dumps at any time
- does not use table locks
- uses commonly available database features
2-Db Log Framework
Intro
- 选择使用
Java; - 选择
Zk实现强一致性,并作成了 插拔式的方案来了替换掉Zk;
Log Processing
框架要求 底层的引擎要能发送事件,这些事件, CDC-LOG-EVENT 要有一些公共的字段:
- 事件的类型:
create,update,delete; - 代表顺序的
number: 这个, 有点头疼 ; - 操作时候的
column state: 我理解是至少修改后,Mysql和Mongodb都一定有修改后,甚至这一次变更的Columns最好也提供一下 , 这个好像Netflix没有强要求 ; - 当前的
Schema, 由于DDL操作会经常修改 ,所以这个提供一下也是必要的 ;
下面是我之前使用
cassandra的设计. 用了很多的字段去确定事务事件的顺序
CREATE TABLE piper.cdc_blogdb (
binlog_file_index bigint,
binlog_file_offset bigint,
binlog_file_xid bigint,
binlog_commit tinyint,
binlog_xoffset int,
binlog_pos text,
binlog_ts bigint,
data text,
full_tbl_name text,
old text,
pk text,
type text,
PRIMARY KEY (binlog_file_index, binlog_file_offset, binlog_file_xid, binlog_commit, binlog_xoffset)
) WITH CLUSTERING ORDER BY (binlog_file_offset ASC, binlog_file_xid ASC, binlog_commit ASC, binlog_xoffset ASC)• binlog_file_offset: 这栏代表了某项事件在特定的二进制日志文件中的位置偏移量。可被用于精确地定位该事件。
• binlog_file_xid: 这是“事务ID”,用于标识特定的事务。在一次事务中进行的全部改动,都会用相同的xid标记,这对于并发交易和回滚是必要的。
• binlog_commit: 这个字段表明是否这个sql已经提交成功
• binlog_xoffset: 这个字段代表了这个事务在特定的二进制日志文件中的位置
Dump Processing
个人理解: 这里的思路是还是利用了 数据日志的幂等性,允许一定的重复 cdc log event, 只要是按照顺序的应用数据,能保证最终一致性, 否则这种设计很不靠谱.
如下图所示,Netflix主要利用了 PrimaryKey 来进行分块, 多 Chunk 并行 Fetch 的思路,因为是一个通用的设计,所以效率肯定不是最好的,所以 并行 在这里显得很关键 ;
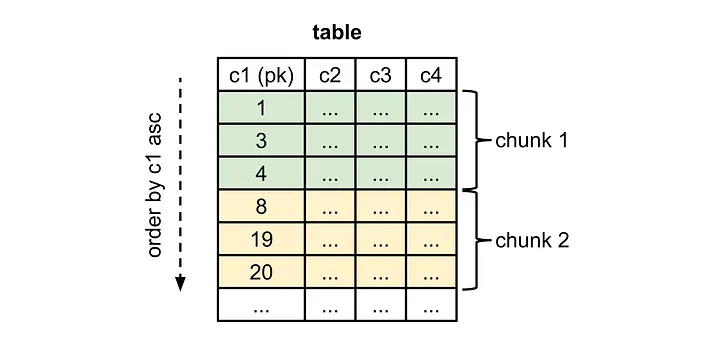
关于如何根据 Chunk 的顺序去实现,下面是一个简单的思路:
如果数据基本连续,通过 minId 和 maxId 切分为多个 Chunk 是非常简单的.
如果数据不连续:
- 我们可以选择
select min(id) from t或者其他的方式来拿到minId作为第一个快的Id. - 然后
select id from t_table where id >= ${prevstartid} limit ${chunkSize},1去依次获取到 下面一个 块的Id - 然后根据并行的数目去 获取这个
ChunkIdRange内的数据去生成统一的事件 ;
Dump 和 Stream Log 如何同时进行
这里 Netflix 做的非常的巧妙. 假设一切都不考虑的话,可以这样实现.
- 停止掉
stream event processor; - 使用上面的
dump策略来走 并行Chunk的Dump操作 ; - 恢复
stream event processor
而这个问题会造成线上 一个 stream event processor 的 超高延迟. 因为 dump 的操作要很久 ;
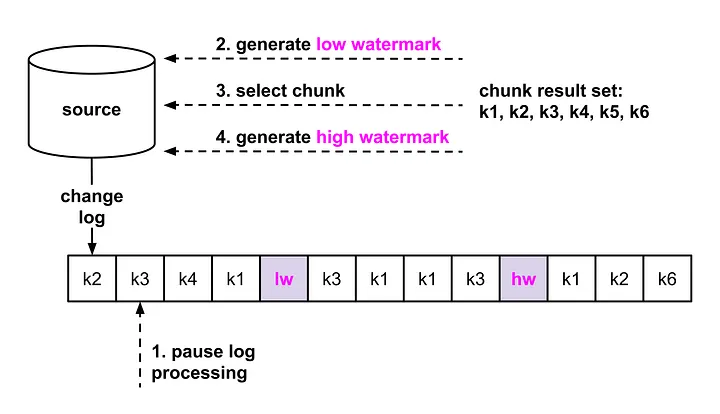
Netflix 的解决方案非常巧妙, 以 Mysql 作为例子.
首先,要有一个和 Source 源同步的事件追踪. 比如说我们在原始的 Db 中创建一张表. 这个表仅仅包含一行数据,用来存储 UUID. 每次更新这个表一定会生成一个 Cdc Event. 这个 Cdc Event 的 Log Seq 就代表这个 修改的时间点,我们称为 WaterMark .
利用上面的 WaterMark 技术我们实现如下的功能:
- 停止掉
stream event processor; - 通过更新水印表,生成一个
WaterMark我们称为 Lower Watermark 代表这次 chunk dump 开始的时间点 ; - 使用
SELECT抽取Dump Chunk放到内存中 - 更新水印表, 生成一个
WaterMark我们称为 Higher WaterMark 代表这次 chunk dump 结束的时间点 ;
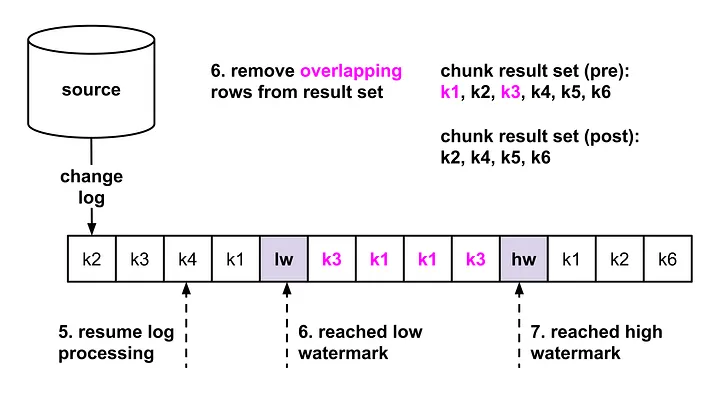
这个时候 这个 Dump Chunk 的数据在内存中,我们要和 恢复之后的 stream event processor 进行 Merge , 这个时候反向理解 ,为什么这么设计! 因为 原始的 Dump Chunk 数据中原始是没有任何东西表达 出这个事件的 sequence 的, 所以 使用 WaterMark 补充了一个区间上去 .
我们恢复上面的 stream event processor ,
我们遍历当前的事件流,因为事件流是有顺序的,同时 需要 merge 的事件是这个 chunk 的 Pk 区间内,这都是比较好判断的 .
- 事件流没有个达到低水印(我们也需要通过 恢复之后的事件流去获取到低水印和高水印,uuid 精确保证会有2个
update事件, 怕的就是没有更新就没有事件). , 那就全部可以应用 - 到达低水印了,证明开始读取了, 我们可以放弃掉
SELECT中获取的数据,如果这个时候流中有对应Pk的话 ,SELECT不修改数据,而在读取时候的修改我们按照stream Log的顺序还原即可, 因此,可以放弃掉这段时间内冲突的数据 ; - 慢慢的到达高水印了,我们可以选择放弃掉 这种复杂的操作,继续正常的应用流数据了,我们把之前的所有数据统一应用即可
然后针对每一个 Chunk 应用上面的逻辑.
Tips
个人认为 这其实是一个 滑动窗口的设计算法,使用在原始的数据源中打桩生成2个高低水位作为滑动窗口的思路非常的巧妙, 但是我认为这个时候应该就不可以并行的 应用
Chunk了吧,应该不能了吧,这个不确定, 当然应用变更那部分确实存在可以 异步的可能性,所以还是能部分并行的, 并行有全局有序的 seq 顺序
- 这个滑动窗口的目的是用来 包裹住
SELECT语句的执行,因为任何数据库引擎不会在SELECT的时候生成CDC, 不是说没有,有那也是另外的机制,例如General_log之类的
下面来自官网的2张图方便理解:
考虑一下:
- 2个 水印操作是 Update 单条数据应该很快
- 中间的
SELECT操作有limit在一个Chunk中也不会太慢
所以大多情况下,不会在高低水印中 出现大量的 CDC Events 造成大量延迟 .
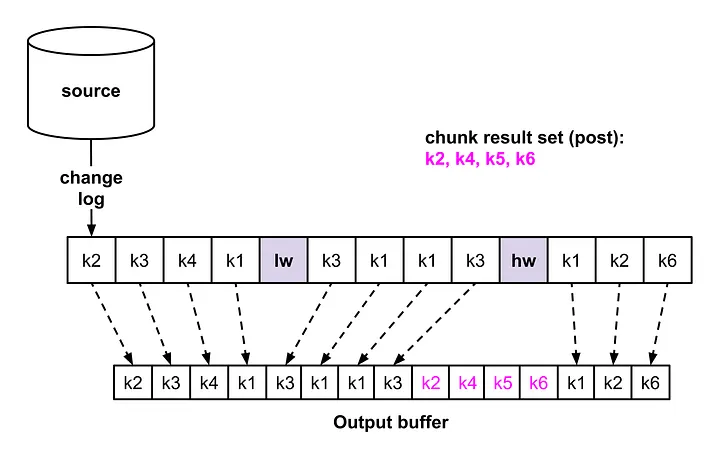
在收到高水印之后我们就可以认为后面全部用 CDC Events Log 恢复正常的流程, 如果写操作在一个单独的线程中处理话,可以是一个 非阻塞操作.
总之是很帅的操作.下图是表达了 交织操作的事件流:
3-Database Support
Mysql:Netflix用的是 老牌的 mysql-binlog-connectorPostGreSql: 用的是 wal2json
而三方插件 JDBC 的支持,需要去实现 Chunk Selection 算法和 Watermark Update 的算法,抽象的也是很不错了。
下面是整理的架构图:
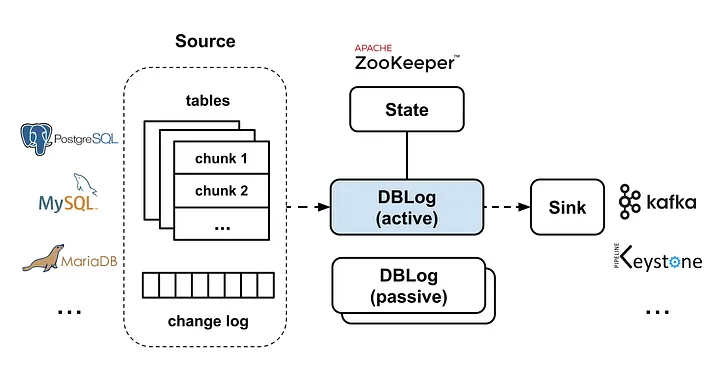
4-HA 设计
这里的 HA 设计采用的是 主备的设计,也就是 只有一个 Zk 选择的 Master 工作.
Netflix会在每个可用区A->Z一般是3个中各部署一个,保证至少一个也是精确一个在正常Work.
Tips
和对等集群设计比,这
Ha被称为Active-passive例如Keep-Alive都是这种思路,会造成一定程度上的资源浪费
5-Netflix 生产架构
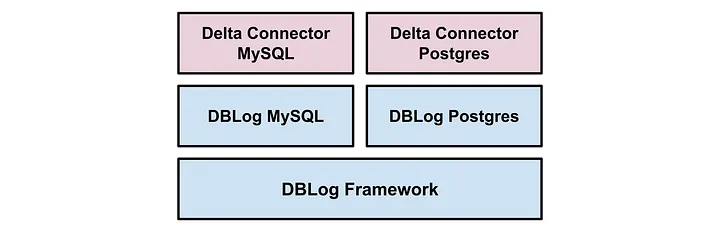
- 2018年左右,
Netflix就大规模落地 Delta, 也就是 他们的同步基础 ; - 在
DBlog至上,Delta有自己各自的针对引擎的 事件序列化器, 而且在输出的时候, 可能不同的引擎事件格式是不同的, 这个很关键,因为目前我选择支持 MongoDb 和 Mysql, 真的很难完全一致
what’more? 这里是 没有覆盖的 features
- 不用.
Lock Table Schema Store: 因为 在工作中可能Schema会经常的变更, 要把每个event跟Schema用外键关联起来了,其实这个Maxwell做的不错,这里应该是一样的 ;- 单调的写入模式,就是异步,应该也是 串行的应用,不让之前的 数据覆盖之后的 ;