1-QuickStart
架构是个难以定义的话题
微服务这些其实说的仅仅是架构的一部分, 一般称为 Architecture Style ;
首先从 单体还是分布式我们可以先简单的分个类:
-
Monolithic: 单体 庞大的架构
Layer ArchitecturePipelineMicrokernel
-
Distributed: 分布式的架构
Service-basedEvent-drivenSpace-basedService-orientedMicroservices
分布式的架构往往更大强大,在许多架构特质上都 更胜一筹, 例如:
PerformanceScalabilityAvailability
但是分布式架构下的8个问题,或者说8个错觉,也是一个非常经典的理论
Network是可靠的- Latency is Zero
- 带宽是无限的
- 网络拓扑是永远不变的, 例如一个 不知道的变化导致 延迟突然增加
- There is only one Admin: 这个主要是 网络造成的复杂性,可能需要大量的沟通成本
- The Network is secure: 很好理解,网络意味着 泄露的风险
- Transport Cost is Zero: 这里是指金钱成本
- The Network is Homogeneous: 这个偏硬件,是指网络设备都是同质的 , 这个其实还好
下图来自左耳听风:

2-Layered Architectures
Topology: 先关注一下. 拓扑
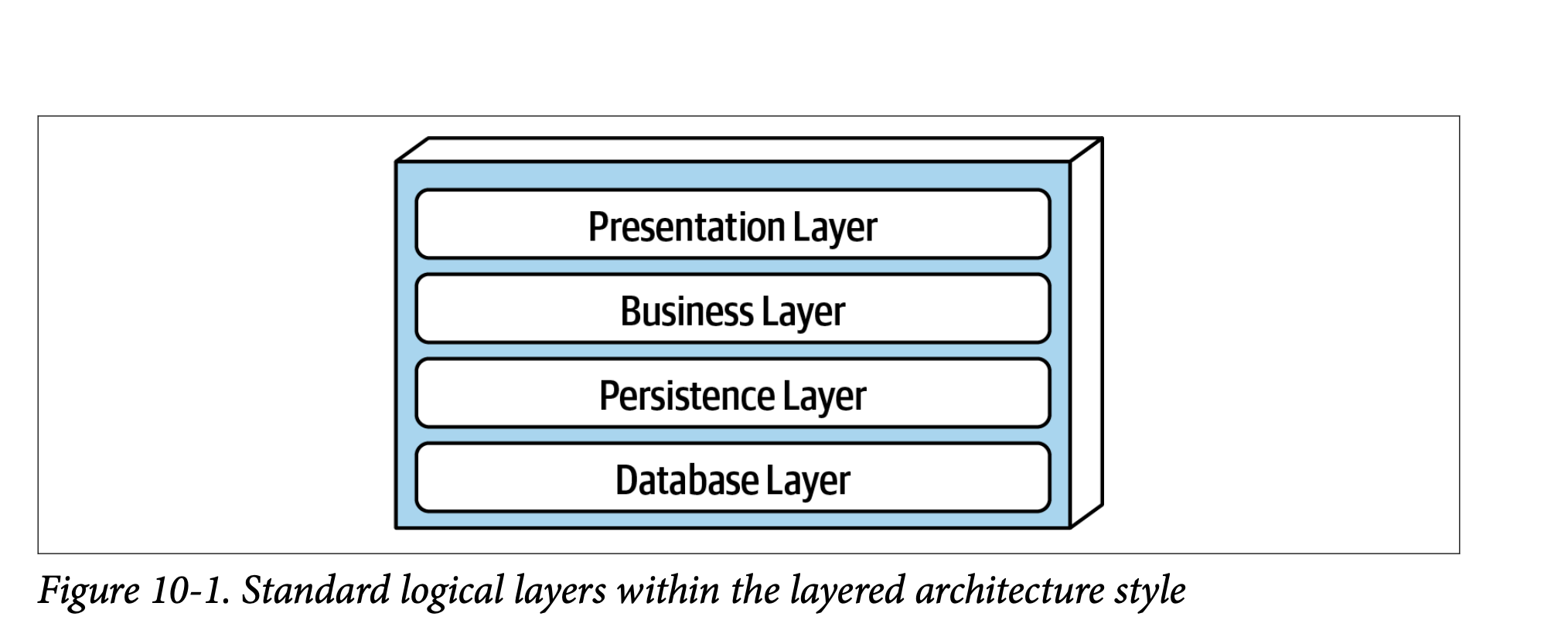
大多数的系统会分为4层, 你可以合并 Biz + Persistence 或者 合并 Persisten + Database 变为3层,或者在 Biz Layer 在抽出来 Mananger Layer 为5层, 甚至更多.
Presentation Layer: 例如XXXController,XXXView做页面 或者 api 的逻辑 ;Biz Layer:XXXService,XXXApplicationService做业务逻辑 ;Persistence Layer:XXXRepo领域对象的仓储 ;Database Layer:XXXDao,直接包含和 基础设施的交互层 ;
下面则是物理层部署的选择, Azurl 可能更喜欢称逻辑上的为 Layer, 物理上的为 Tier.

分层架构简单,但是不能很好的 和
Domain的结构组合起来
- 每一层是一个 功能层的抽象

- 什么是
Layer的Closed? 这个Layer是关闭的,想要直接访问下层是不行的 - 这不是 强制的 , 你可以选择
Business Layer从Closed -> Open, 表示允许直接使用Persistence. Layer为Presentation Layer服务
再举个,增加
Layer的例子, 我们的Business Layer中有很多可以复用的代码,希望能提取一层新的Manager Layer或者Service Layer放一些通用的逻辑

- 我们需要保证这个新增的
Layer是Open的
分层的一个典型
Anti-Pattern, 反模式,由于我们的这种设计和模式 导致的问题
假设我们有 4层, 而大多数的请求都是最简单的 CRUD, 意味着一个 Persistence Layer 都可以完成, 而上面的 Biz Layer 只是强行调用一次. 这样的代码如果多了,则是一个信号,这个 Layer 设计的有问题.
这个时候有2个办法:
- 进行
Layer的合并,这个比较 极端,不是特别建议 - 把
Layer的状态从Closed -> Open, 比如很多读取的服务,甚至可以直接通过Database Layer去获取数据
比如说对于个人的实践而言,对 Command 和 Query 的 Pattern 使用不同的 Layer 规则可以更加的 契合他们的场景.
Why Use this Architecture Style.
分层架构的风格是一个很好的起点, 将来可能避免不了改造,但是作为 从 0→1 他永远是值得考虑的选择.
下面解释一下:

- 根据 业务场景在 当前阶段选择, 架构的
Simplicity和Overall cost这2个特质 , 在业务架构的初期 从 0→1 是非常重要的 . So!
3-Pipeline Style
管道的设计模式非常的经典,例如 Bash, Zsh 等终端语言都使用这种方式.
他更像一种设计模式. 而不是一种架构风格,原作中 作为了一种 大型单一系统中设计风格,但是从实际的场景中, 他不仅仅局限在 单体的架构中, 例如 MapReduce 甚至后面的 Spark 的 DAG 都有 Pipeline 的思路 .
在 Azure 的理解中也是一个 Pattern, 可以参考 Pipes And Filters Design Patterns .
有趣的是,我们经过能看见这个架构 越来的越多的出现在 数据处理的领域中, DataPipeline 是非常常见的设计,不管是 Flume, Vector 等等.
下图来自 Azure
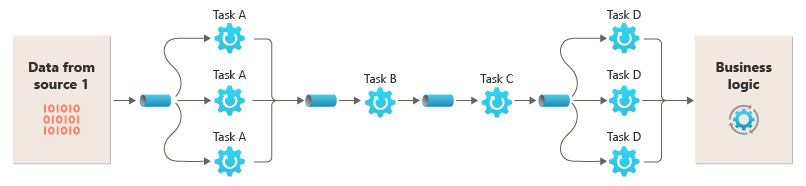
这种设计中 会分为 Pipes 和 Filters. 而且很契合 函数式编程
Pipes: 他主要是在Filters中互相通信的组件,Filtesr则是 实现我们业务规则的主要部分 ; 通常 一个Pipeline是一个 单向的,Point-To-Point的设计,双向的,广播的很少见Filters: 实现我们业务规则的组件, 这里是一个 广义上的Filter, 不是 狭义的过滤功能- 要符合 函数编程的通用设计: 最好是 一个单一的功能,是 无状态的.
- 一个复杂的功能,最好用多个
Filter组合实现 - 一般按照类型至少可以分为:
Producer或者叫做SourceTransformer: 例如Map,Reduce这种选择部分或者所有数据进行转化Tester: 用于测试Consumer: The termination point for the pipeline flow. 终止节点
老故事, More Shell, Less Egg
tr -cs A-Za-z '\n' |
tr A-Z a-z |
sort |
uniq -c |
sort -rn |
sed ${1}qDonald Knuth 被要求实现一个文本处理的功能:
- 读取一个文本文件
- 找到最常见的
n个单词 - 然后打印单词和其频率的 排序列表
他写了一个 10多页的 Pascal 代码并设计了一个新的算法.
然后 Doug Mcllroy 使用了上面的 shell . 同时也从另一个面说明了 函数式编程在抽出公共组件的 独到之处.
当然也有很多人会抱怨 Lambda 地狱的事情, 最近在 技术平台上看到不少 新老程序员的故事。
我个人的理解是,上面的优雅之处 在于每个 function 都有 良好的可读性, 无状态 等等 , 如果你完全不了解函数式编程 只是生搬硬套 可能是 适得其反.
Tips
每个
filter都是隔离的运行的, 会被提供足够的Context来执行,所以信息的传递成本是一个主要的考虑点,尤其在分布式的环境中
4-Microkernel
微内核设计 ,往往用来实现
Plugins系统, 因为出现的年代比较早,这里写一个简单的例子
这个时候应用的逻辑 会被 分散在 Core System 和 一系列的 Plugin Component 中.
Eclipse JetBrains IDE VsCode 等等中都是这种设计.
原书用了 1个设备评估的例子
public void assessDevice(String deviceID) {
//
if (deviceID.equals("IPhone6s")) {
assessIPhone6s();
} else if (deviceID.equals("iPad1")) {
assessiPad1();
} else if (deviceID.equals("Galaxy5")) {
assessGalaxy5();
} else ...
}改成使用
public void assessDevice(String deviceID) {
String plugin = pluginRegistry.get(deviceID);
Class<?> theClass = Class.forName(plugin);
Constructor<?> constructor = theClass.getConstructor();
DevicePlugin devicePlugin = (DevicePlugin) constructor.newInstance();
devicePlugin.assess();
}大致的架构图如下.

- 不管是
Domain Partitioned还是Tech Paritioned都可以配合使用.
Examples
从实现的角度,可以是 Shared Libs, 例如 Jar, DLL, Gem .
各种语言体系都提供了 Runtime 的支持, 例如 Java 的 Open Service Gateway Initiative(OSGI) , Penrose, Jigsaw, .NET 的 Prism 等等.
甚至 Plugin 可以是 远程的, Remote Plugin 的成本和危险性会高一些.
Dubbo中使用SPI来实现插件的管理,Netty还是Mina.Slf4j在运行的时候检查有哪些 实现,例如Logback,Log4j..golang中Echo的功能组件都是各种的MiddleWare- …
Tips
在业务上 还可能会用
ZkConsul这种组件去动态注册插件, 或者 使用 数据库存储等等. 都是 微内核的一种设计,核心就是要 标准化非核心功能的接入方式, 并且和核心功能解耦, 这样更像一种设计模式
说 微内核设计 往往也绕不开操作系统
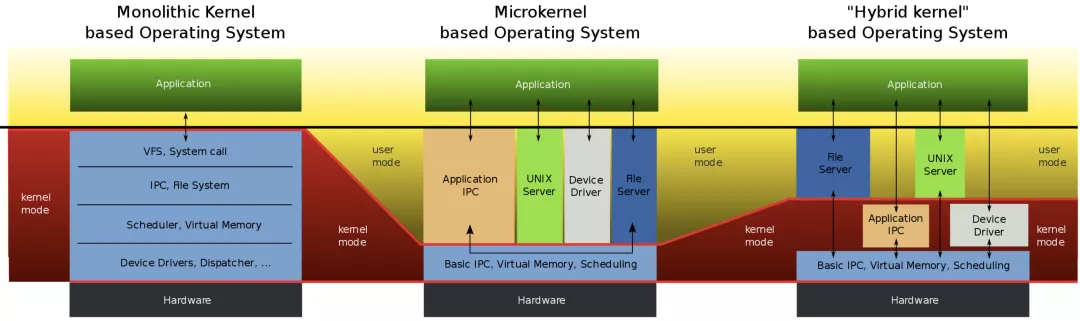
微内核和宏内核 在操作系统内核中的设计也一直是大家讨论的焦点,例如:
Windows偏向是使用 微内核设计.- 内核仅仅完成内核必须完成的任务, 例如 中断,进程的创建,调度和通信
- 内存管理,文件系统,设备的各种驱动不属于内核,是作为用户态的进程
Linux偏向是使用 宏内核设计- 内核负责上面的 所有任务
从设计的角度上来讲 各有优劣.
微内核的 设计有可插拔性,容易迭代和更新,但是 各个组件之间的协调会变的更加的复杂,单纯从性能的角度可能需要更多的时间,但是这也不绝对,因为技术是发展,尤其是现代的硬件和芯片技术发展,性能都很 ok 的.
Tips
这里想表达的观点是 技术上都是取舍,没有优劣. 例如 现在 先是一波 微服务热潮, 然后最近一段时间内的 宏服务热潮, 可以优化性能. 性能重要还是迭代重要, 是没有 答案的问题.
但是我们发现 微服务架构中 也会有和 微内核架构中 非常类似的问题, 各个组件的协调成本会变得非常的复杂, 而且网络的 8个错觉 也会让 延迟和性能的挑战陡增,但是从 大体来看,微服务架构依旧是 顶级架构,是时代的进步, 性能从来都是唯一的架构考虑点, 他是一个 重要的 架构特质.
而且有趣的是上面图中的第三张,混合架构. 这会更加的复杂,但是确实有操作系统在这样做, 既要 微内核的灵活性,又要宏内核的 性能,这就很 博德之门了, 既要又要.
比如说苹果, macOs 和 Ios 使用的内核架构是 XNU, 这是一种混合内核的设计, XNU 内核中包含了一个名为 Mach 的微内核, 也集成了 FreeBSD 宏内核的组件, 装载在内核空间的驱动和协议栈可以直接访问 Mach 提供非常低级别的 API.
甚至个人有一个错觉, 最近一段时间内的 中台设计和拆中台设计,也是既要又要的尝试. 把多个微服务组件组合起来提供功能 给多条业务线使用. 是一个 宏服务, 高效 高性能. 而中台本身的设计又是微服务,只是很多家落地的都不够好.
微内核架构和微服务架构有一样的通信问题
- 微内核中2个
Service由于不在同一个 内存空间, 所以通信往往要走一次内核中转,内核提供了统一的MessageBus - 而在 微服务中,2个
Service可以选择 直接通信,也可以走 一个MessageBus
这2种通信方式 也正对应了 微服务中的 Rpc 和 Mq 这2种通信方式.
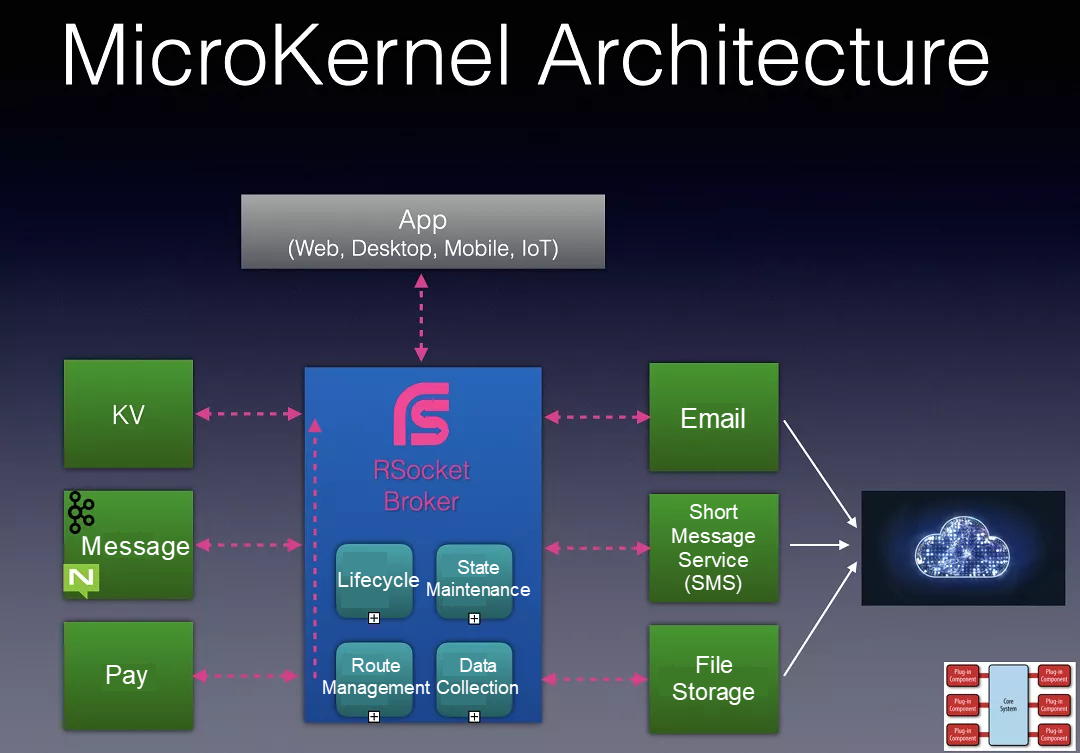
而微服务中从 自定义协议 → Grpc Based On Http2 → RSocket 都是 为了解决让2个 Service 之间进行通信的.
架构特质

5-Service-Based
技术部门的扩大 → 组织架构的调整 都会更偏向按照业务拆分,技术上也一样,之前的思路都是按照 tech layer, 现在则会在 顶层多一个 domain Partition 的思路 .
而此时的技术实现还偏向 Service Locator Pattern
这个是在
User Interface上的偏差

- 这里主要是
User Interface的选择, 一般上面的都不会这样用,而是使用一个 专门的 网关或者中台出口去 聚合.
这里主要说一下数据库的偏差
如果业务架构从一开始没有做任何的 Domain-Paritioned 工作,从一开始就是 Tech-Paritioned 的方式,直接一步到位微服务是 不现实,而且困难的,这个时候 SBA 就是一个非常合适的方式,因为 数据库层面上,这个架构下有很多的 偏差供我们选型.
一开始我们做好业务划分,可以继续改代码,然后仅仅使用一个 Database . 甚至是把 database entity 抽为一个 libs 来给所有的 业务方复用, 但是这意味着 DDL 就要升级整个版本

等业务代码改的差不多的时候,我们把关注点放回到 database. 我们可以考虑如下的 架构方案.

-
分为一个个的逻辑库. 此时代码应该已经足够的清晰了. 在分层架构的时候,一开始就可以考虑 逻辑库划分
-
注意到有一个
common_entities_lib
Tips
要提前抽出 lib ,而且一定要做版本控制,例如 tag, 同时配合一些自动化的
doc工具等等
lib实践上最好一开始就划分为biz,infra2个迭代路径,因为infra这种变化很少, 但是业务上的lib,比如上面的,在敏捷开发的如今其实迭代频率理应很高.
6-Event Driven
Event Source Design pattern
EDA来自经典的 事件回溯的设计思路
这种设计思路是每次修改记录不可变的修改事件,然后读取的时候 Merge 或者定时 Merge 为各种各样的数据视图
在数据分析领域,存储领域,业务设计领域中都很有价值
EDA 分为2种: Broker 和 Mediator, 前者比较简单,类似常见的
MQ, 后者比较复杂, 工业级别的消息总线

下面是个人偏好的一些 mq.
要注意, mq 的所有 event 也是应该有 schema的,并且配合版本管理的.
broker 的这种模式 拥有非常多的优点,同样缺点也很多.

- workflow 的问题, 回调,如果 workflow 复杂,没有中心的地方统一管理
- error handling : 只能各自独立自己的错误
- …
而 Mediator 为了解决这些问题,而 又引入了极高的复杂性.

需要一个专门的中间层来处理这些问题.
如果 没有特别复杂的 event 流可以考虑如下的解决方案:
如果 workflow 再进一步的复杂可以考虑如下的方案:
Apache ODEOracle BPEL Process ManagerBusiness Process Execution Language
Tips
Mediator 设计往往 用电商系统做为例子是比较好的. 配合现代化的各种组件,内容很丰富,这里仅仅是考虑点
Async: 异步化的能力 ,性能,解耦,流量整形And So on;Error Handling: 错误处理, 补偿,幂等 ;Data Loss: 二阶段消息,补偿,死信队列 ;Broadcast: 广播能力 , 这个是可选的 ;
EDA 其实是 Event-Based 的通信方式,跟传统的 Request-Response 模式还是有本质的区别的

7-Micro Service
微服务来自于 领域驱动设计 -DDD
- DDD 到底是垃圾还是银弹 : 这篇文章是用 非常通俗的语言去理解
DDD, 不一定完全准确,但是确实是非常好的入门内容
尤其是其中的有界上下文, 他代表了一种想法, 一种有边界的 解耦风格.
当定义一个 Domain 的时候, 有一个 聚合根,有很多的实体 和 值对象, 他们的 domain 代码中定义了他们的行为. 核心在于有界,ddd 其实做出了非常多的努力,不管是在应用 层面还是数据层面.
- 一个领域只能有一个聚合根, 本身聚合根的选择就确定了界限,也是最难的一步,是大一点好,还是小一点好
- 如果 数据库设计没有体现出领域 之间的 限界独立,那微服务的意义不大;
- 在一致性上也有明确的参考目标:
- 领域内追求强一致性
- 领域外追求最终一致性
软件的第一法则是 权衡和取舍,复用性高的 负面作用 就是 耦合度高, 当我们在实现的时候想要更好的重用,一般都是 继承 或者组合,配合一些设计模式来实现,不管是继承还是组合,就是 耦合.
- 一个很粗暴的理解,你复制粘贴其实 没有重用,但是耦合程度也低, 这是不对的,但是 你设计过度,高度复用,但是耦合度高,也是不对的
微服务的主要目标则是高度解耦,而不是复用. 追求 数据层面和应用层面的 完全独立,可独立部署的闭环.
拓扑图.

微服务 不是 微服务
- 按照
Martin Flower的解释, 这是一个Label, 而不是Desc, 只是因为这种思路需要一个名字,所以叫microservice, 不是说 粒度要微 的意思. - 很多人错误的理解了 这个含义,而把服务的粒度设置的太细. 一句话, 没有人说微是对的, 关键是基于聚合根构建一个 独立的单元,不管是数据,还是应用,还是部署上
所以问题依旧是如何选择 聚合根的粒度,也就是如何拆分服务, 确定边界.
确定边界的三个思路
Purpose: 业务目的和能力, 这个是 最好的 灵感来源, 尤其是 领域专家,好的情况下,他们非常的 内聚, 代表了应用一个重要能力, 而且 因为解耦导致的 重复性成本也会大幅度降低 ;Transactions: 事务的角度,因为 分布式事务 复杂废钱, 所以 2个服务中要 走分布式事务协调,不如优先考虑一下 2个领域合并为一个?Choreography: 编排角度, 如果 为了编排某一个能力,例如小团队搞电商,一个订单创建需要 大量的服务之间的通信才能完成任务, 不如考虑合并到同一个DOMAIN- …
很少能做出完美的 粒度选择,其实就是没有,如果确定要走这条路,就要 舍得为他而迭代
微服务落地的考虑点
Data Isolation: 数据的隔离 是必须的 . 真的不行,逻辑隔离一下,统一一下命名规范 ;- 更有趣的讨论是
CQRS的风格,这里不展开, 但是核心是思路为 读写模式 通过数据复制的思路构建不同的 数据存储
- 更有趣的讨论是
Communication RulesOperational Reuse: 运维的通用 往往是 最大的难点之一,K8s和Isito类似的编排基本是 当前 当仁不让 的选择
Operational Reuse 往往现在都是配合 sidecar 模式落地.

Sidecar来源于王挂内模式,之前的思路 是一个 共享的独立服务,或者一个共享的库 供大家使用Sidecar被分为 控制平面和数据平面,类似网关一样接管了所有的流量,然后基于全局统一的配置下发来实现 动态的功能
通信方式
第一个考虑点是同步还是异步,二者的 工作path 基本不同. 但是不管是哪种,都要有 配套的 Schema Registry, 哪怕是 REST , 也要规范.
Netflix 的 Proto 要支持三种, REST, GRPC, 和 GraphQL, GraphQL 在这个场景是有个有意思的决定.
RSocket 的底层实现似乎也还不错,甚至有一些 单语言的团队会使用一些 强语言的通信方式.
总之,为了将来的团队,你可能需要从一开始考虑发布的 服务就要支持多种 通信方式.
Java系可以考虑 Armeria 这种方式, 他没有做底层的规定,对每种 通信方式做一个通用的Adaptor设计
关于编排和调度
一种 在领域设计中的看法会分为, 核心域,支撑域 和通用域 来做 战略和战术的划分. 但是微服务本身是强调解耦,不需要一个中心的 协调节点. 但是为了防止出现 服务的 依赖环图,创建局部的协调器 对于 Clean Arch 来说也是必要的.
在编排中如何 有一个清晰的服务依赖关系图也是非常重要的. 可以看下面的2种设计之间的取舍,是否要抽出一个来专门协调调度关系的组件

vs

Transactions Saga?
Saga是一种设计模式, 用来解决全局事务,Saga会把全局事务分解为本地的小事务,是 相对成熟的方案,但是 成本极高
一般而言,要实现一致性.
- 应用层面还是 走 补偿,幂等的思路
- 数据库层面则是
Raft,ZAB
选择 SAGA 往往都不是个好决策.
总结 微服务.

8-Other
- Orchestration-Driven Service-Orient : 企业合并的时候用到
- Space-Based