1-Intro
2-Shared-Nothing Design
Core Counts Grow, Clock Speeds Stay Constant
- 摩尔定律已失效, 单核的处理能力基本 Stay Constant, 现在提升性能的方式一般是 Core Counts Grow ;
- Core Counts 增长导致的问题是 多个核心之间的协作设计会变的越来越重要.
Meanwhile, I/O Continues to Increase in speed
IO 一般认为是 网络IO 和磁盘IO, 这些设备的性能还有很大的提升空间,而且在稳定的提升.
在 小 packet 的情况下,可能 CPU 的处理速度反而成为了瓶颈.
A 2GHz processor handling 1024-byte packets at wire speed on a 10GBps network has only 1670 clock cycles per packet.
这个时候, CPU-Core 的可伸缩性就非常的重要. 而 Stateless 的设计关键在于 Share On Nothing .
Problems About Sharing Of Information across cores
- 锁和同步机制:
CAS,RCU,Mutex,SpinLock,Semaphore, 具体了解他们的开销可以参考 Linux-并发原理 - 缓存的一致性问题,
L1,L2,L3,MESI协议和他们的变种, 推荐 程序员应该知道的缓存知识 - 谐波效应: 一个核心的延迟蔓延到其他的核心中, 从而导致整个系统的性能下降
- 虚假共享(
Flase Sharing): 同上面,是一个常见的东西,跟Cache-Line有点关系
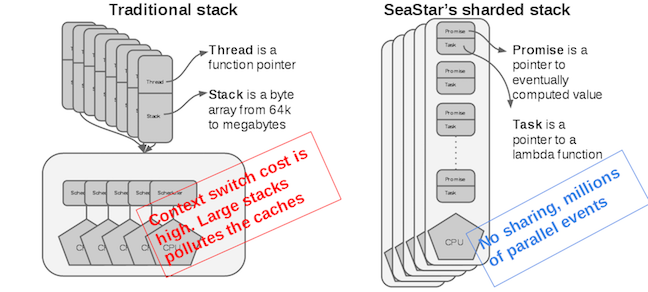
The Seastar Model: Shared-Nothing
Seastar 会给在每个 Cpu-Core 上运行 一个 Application-Thread, 然后 跨 Core 之间的使用 Explicit Message Passing.
这个设计就很通用, 个人理解 理念上跟 Golang 的设计类似, 虽然的是协程, 但是原理也是这样的, 讲的就是一个 CSP: Communicating Sequential Processes
只是 Seastar 的设计就跟底层一些, 为了 Core 的通信做了大量的工作,实现的核心的是一个 高性能的非阻塞机制, High Performance non-blocking communication primitives to ensure preformance is not degraded
举个例子: 一个会话的2个请求去了不同的 Cpu, cpu0 和 cpu1, 首先 要尽可能的避免跨 cpu 的通信, 非要通信不可,例如 cpu0 必须转发一个请求给 cpu1, 就要通过高性能的消息机制去做,而不是直接调用.
Example for Explicit Communication Between Cores
最简单的例子是:
smp:submit_to(cpu, lambda)这是 典型的 Future , Promise 的设计. 具体可以参考 Futures and promise design
- 会把
submit的lambda包装为一个Promise, 这个lambda返回的结果,就是和这个Promise对应的Future
使用如下:
smp::submit_to(neighbor, [key] {
return local_database[key];
}).then([key, neighbor] (sstring value) {
print("The value of key %s on shard %d is %s\n", key, neighbor, value);
});- 上面的通信操作可以理解为对标 数据库中的 Lock 操作*
除了上面的 lambda 跨核通信, 还有其他的方式:
- 例如一个
VALUE,broadcast给所有其他的CORE; - 还可以通过
broadcast广播一个lambda给所有的cpu实现一个类似map的功能, 然后 收集所有CPU的计算结果, 然后执行 一个transoform去实现一个reduce的架构 ;
3-Networking
Linux 的 Tcp 网络堆栈
Linux中可用的传统网络功能特性齐全,成熟,性能高。然而,对于真正的网络密集型应用程序,Linux堆栈受到限制:
内核空间实现:将网络堆栈划分到内核空间需要执行成本高昂的上下文切换来进行网络操作,而且必须执行数据复制以将数据从内核缓冲区传输到用户缓冲区,反之亦然。
时间共享:Linux是一个时间共享系统,因此必须依赖于慢速,昂贵的中断来通知内核有新的数据包需要处理。
线程模型:Linux内核是高度线程化的,所以所有数据结构都受到锁的保护。虽然Linux经过巨大的努力已经变得非常可扩展,但并非毫无限制,大规模核心计数时会出现争用。即使没有争用,锁定原语本身相对较慢,影响网络性能。
通过使用Seastar基本原语实现的用户空间TCP/IP堆栈,可以避免这些限制。Seastar原生网络享有零复制、零锁定和零上下文切换性能。
备用的用户空间网络工具包,DPDK,设计用于快速数据包处理,通常每个数据包少于80个CPU周期。它和Linux无缝整合,以利用高性能硬件